· David Göschel · DevOps · 4 minuten Lesezeit
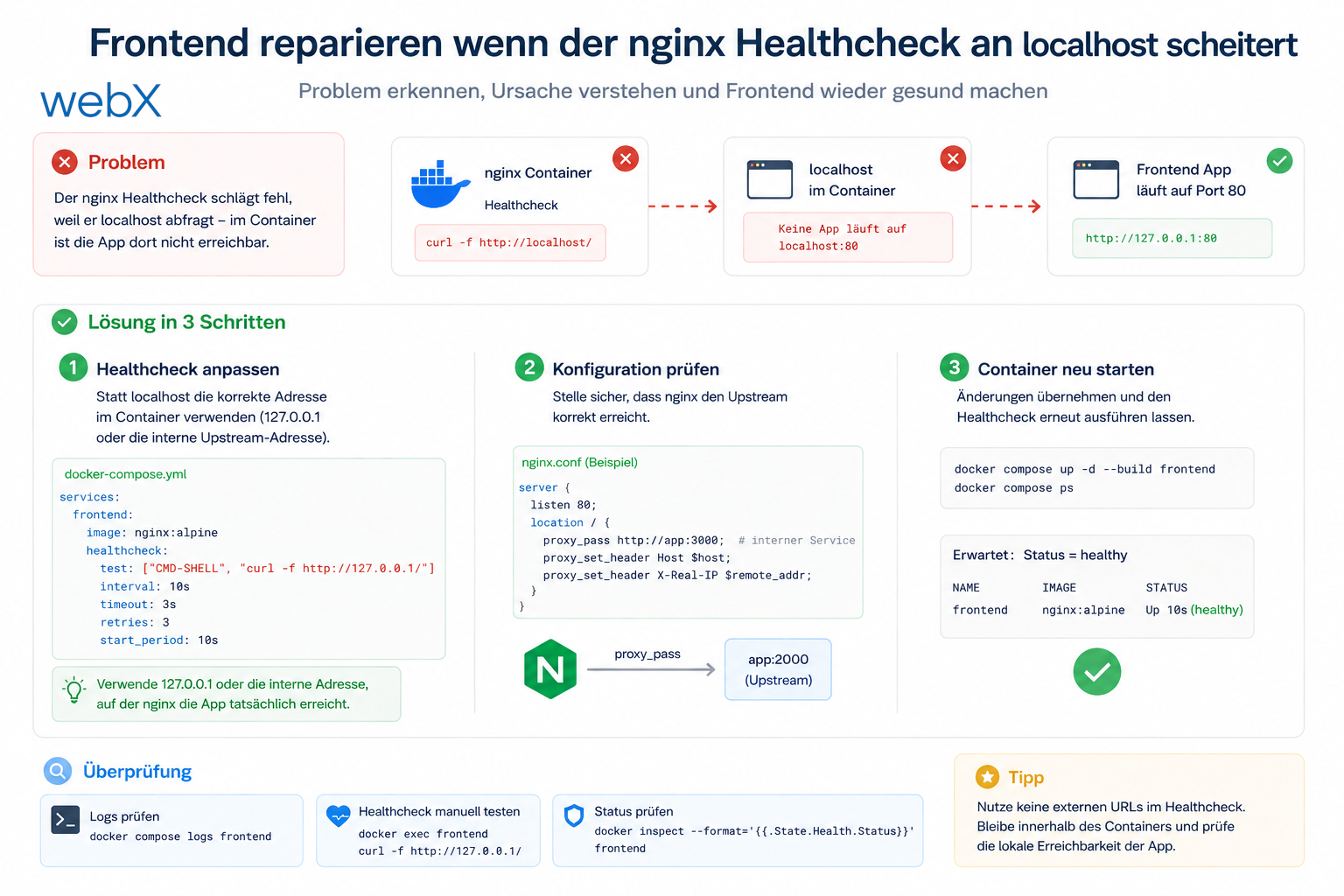
Frontend reparieren wenn der nginx Healthcheck an localhost scheitert
Der Frontend Container war gebaut, lief und war trotzdem unhealthy. Die Ursache war eine kleine Alpine Falle: BusyBox Wget suchte localhost zuerst über IPv6 und nginx lauschte nur auf IPv4.
Inhalt
- nginx Healthcheck in Docker beheben wenn localhost auf IPv6 zeigt
- Warum
localhosthier falsch war - Die saubere Korrektur
- Warum ich
curlstattwgetnehme - Was ich aus dem nginx Healthcheck und IPv6 Problem gelernt habe
- Alle Artikel der Serie
nginx Healthcheck in Docker beheben wenn localhost auf IPv6 zeigt
Der Frontend Container lief. Der Build war erfolgreich. Trotzdem meldete Docker den Container als unhealthy.
Die Log Meldung war unspektakulär.
wget: can't connect to remote host: Connection refusedGenau solche Fehler nerven, weil sie so klein aussehen. Das eigentliche Problem steckt oft nicht in nginx selbst, sondern in der Art, wie der Healthcheck aufgerufen wird.
Warum localhost hier falsch war
Der Container basierte auf nginx:alpine. Darin steckt BusyBox wget. Und BusyBox behandelt localhost nicht immer so, wie man es im Kopf hat.
Im Container konnte localhost zuerst auf ::1 zeigen, also auf IPv6. nginx lauschte aber nur auf IPv4.
server {
listen 80;
root /usr/share/nginx/html;
index index.html;
}Für den Browser war das egal. Für den Healthcheck nicht.
Die saubere Korrektur
Ich habe zwei kleine Änderungen gemacht.
- Der Healthcheck nutzt jetzt
127.0.0.1stattlocalhost. - nginx lauscht zusätzlich auf IPv6.
healthcheck:
test: ["CMD", "curl", "-sf", "http://127.0.0.1/"]server {
listen 80;
listen [::]:80;
root /usr/share/nginx/html;
index index.html;
}Damit ist der Check robust genug für den Container und trotzdem simpel genug, um ihn später noch zu verstehen.
Warum ich curl statt wget nehme
curl ist in nginx:alpine verfügbar und verhält sich in diesem Fall verlässlicher.
Das ist kein magischer Trick. Es ist nur die weniger fehleranfällige Variante für einen Healthcheck, der wirklich nur wissen will, ob der Webserver antwortet.
Ich will in einem Healthcheck keine Nebenlogik. Ich will nur eine klare Aussage:
- Antwortet nginx auf
127.0.0.1? - Dann ist der Container healthy.
- Wenn nicht, ist etwas wirklich kaputt.
Was ich aus dem nginx Healthcheck und IPv6 Problem gelernt habe
Ein Healthcheck ist keine Nebensache. Er ist Teil der Architektur.
Wenn er falsch gebaut ist, erzeugt er falsche Signale. Dann sieht ein funktionierender Container kaputt aus und die Suche geht in die falsche Richtung.
Für mich ist die Regel jetzt klar.
- In Alpine Containern lieber explizit
127.0.0.1verwenden. - Bei nginx zusätzlich IPv6 aktivieren, wenn der Stack später sauber dual stack sein soll.
- Einen Healthcheck immer so schlicht wie möglich halten.
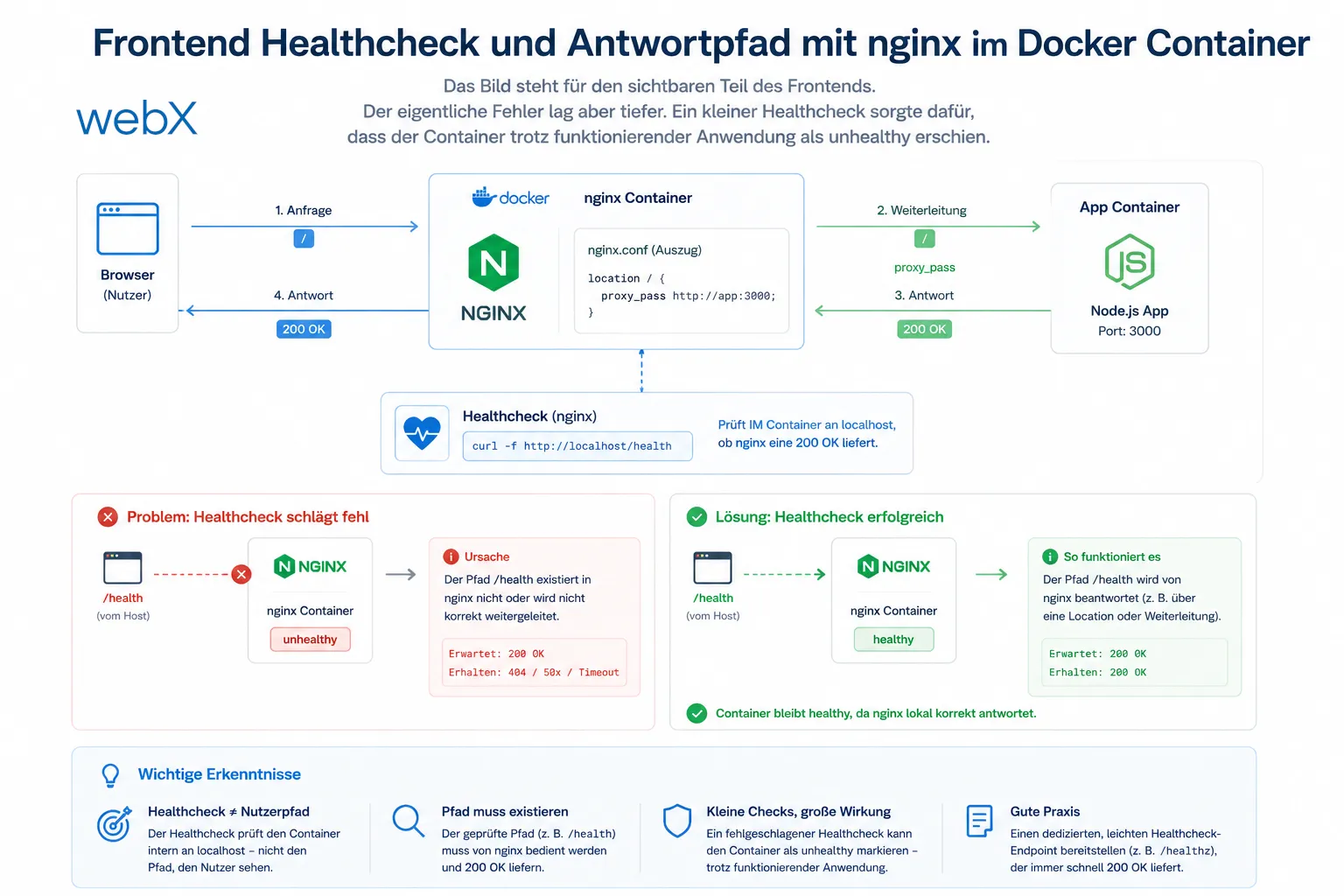
Das Bild steht für den sichtbaren Teil des Frontends. Der eigentliche Fehler lag aber tiefer. Ein kleiner Healthcheck sorgte dafür, dass der Container trotz funktionierender Anwendung als unhealthy erschien.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
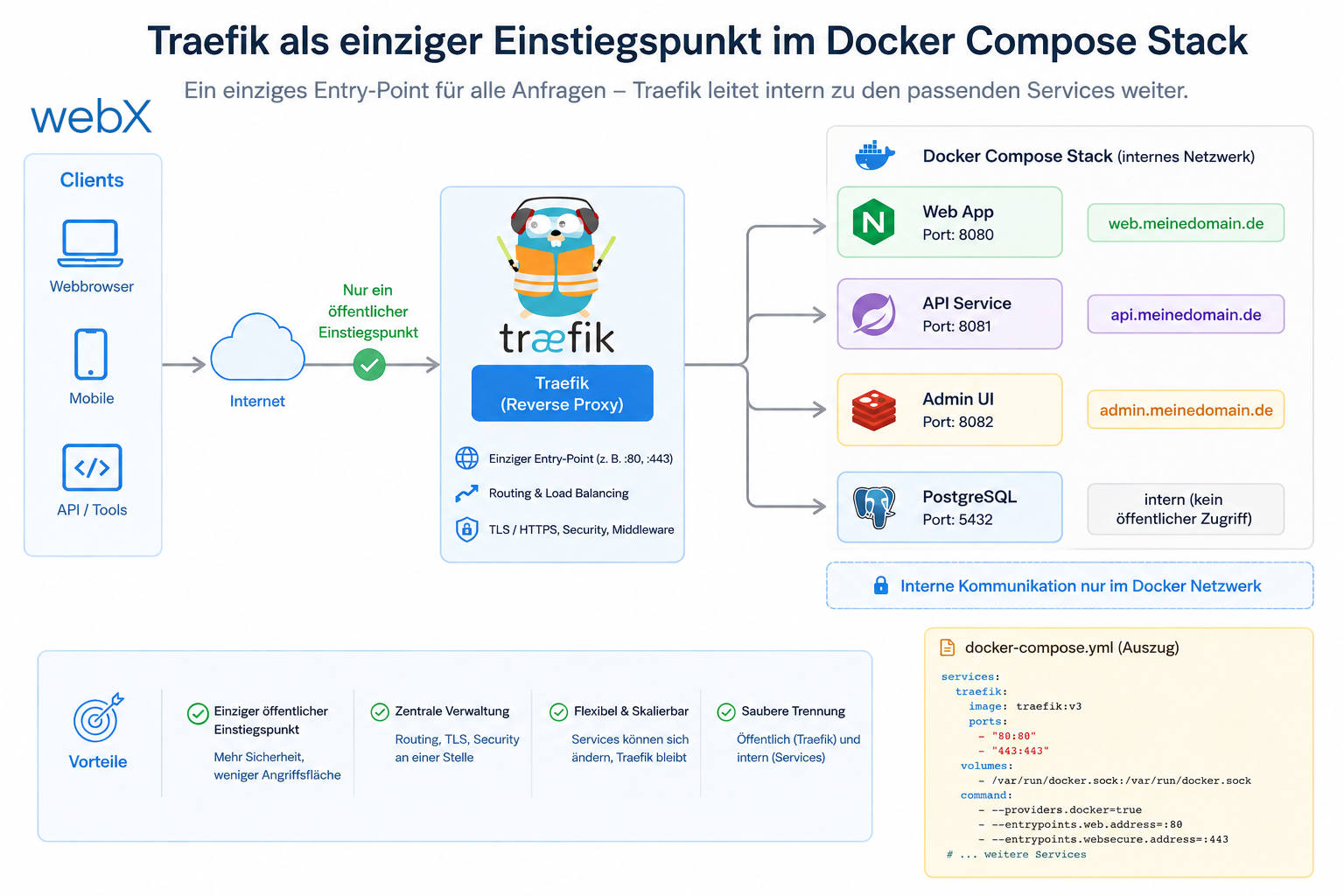
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
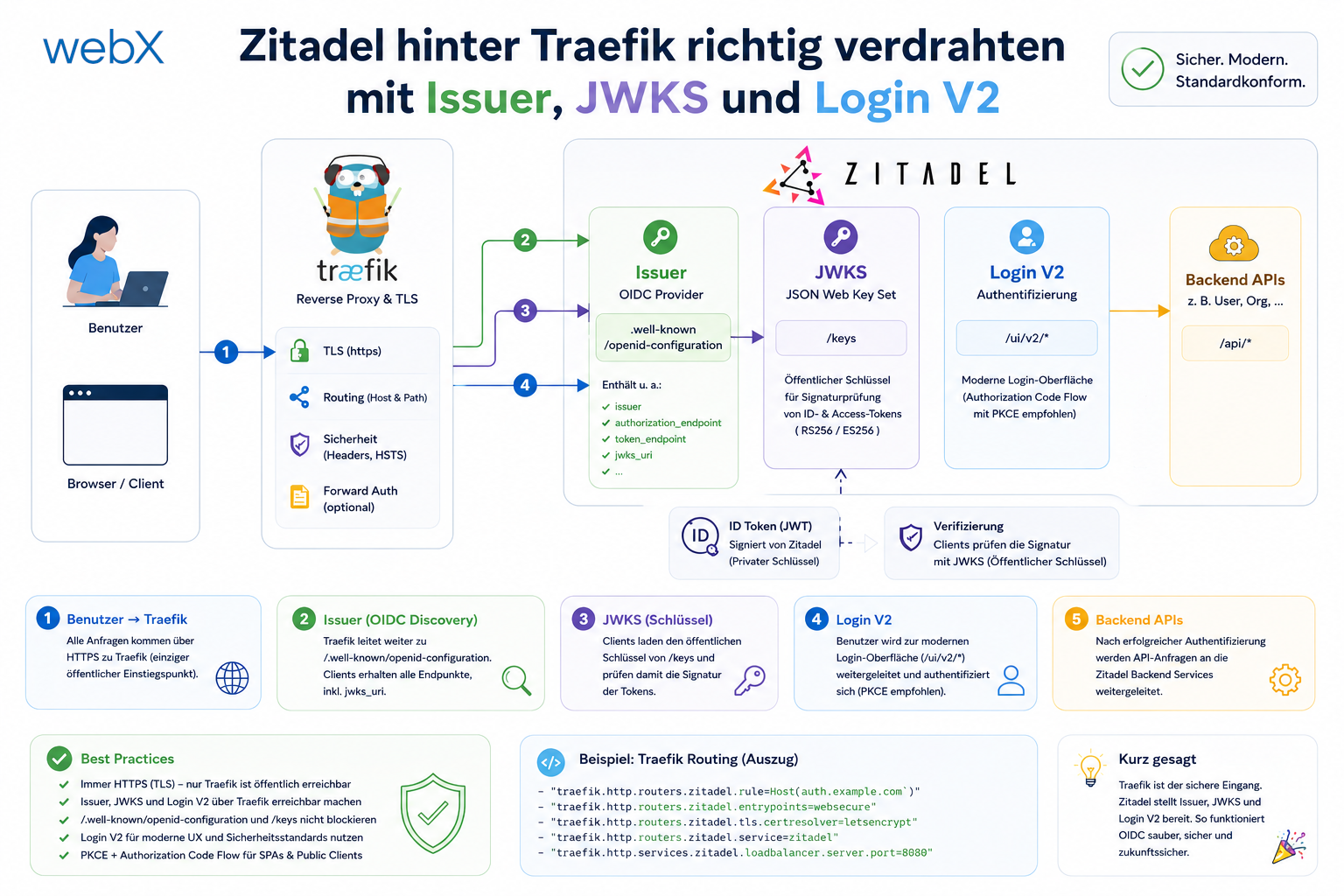
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: (dieser Artikel)
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
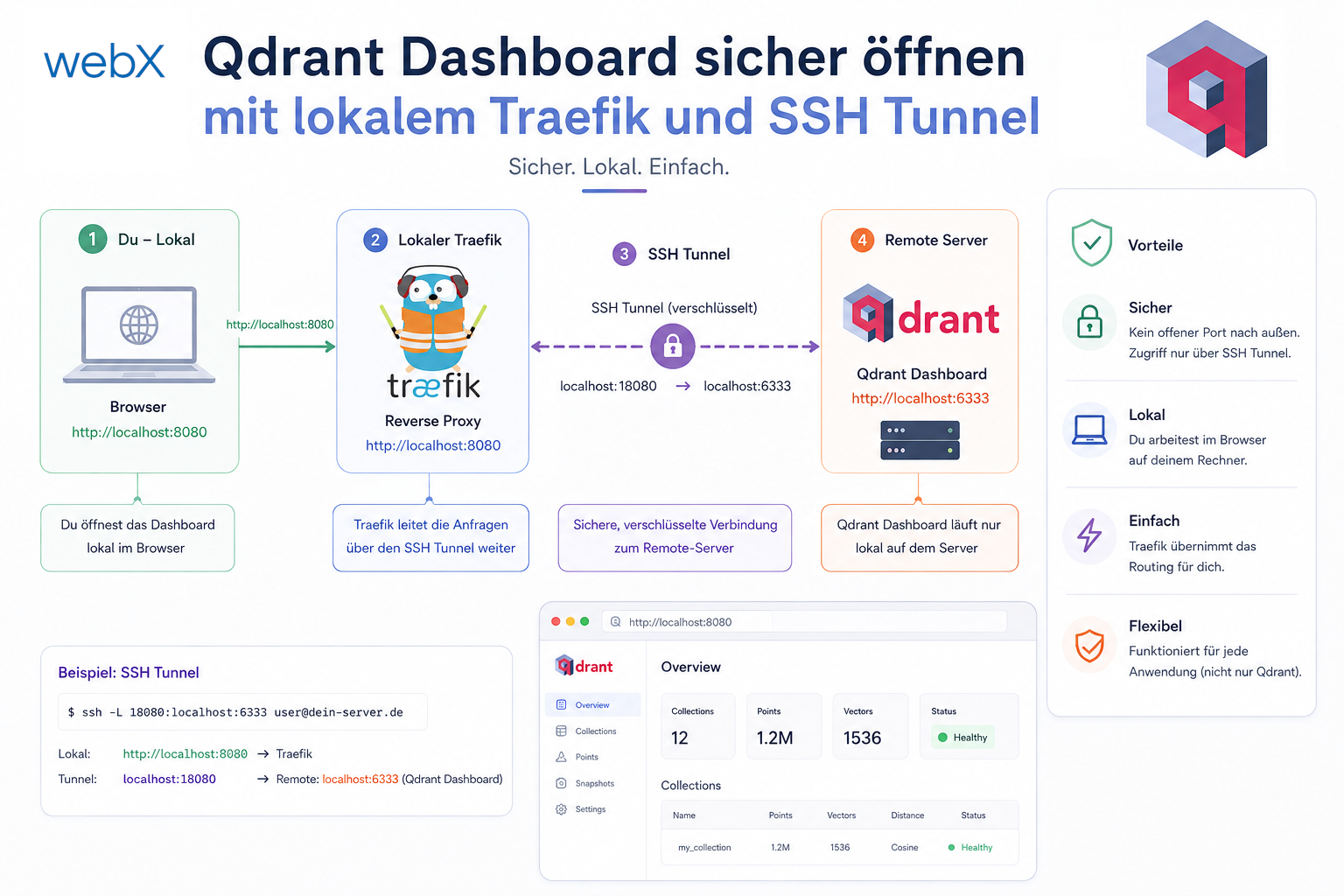
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du baust gerade einen ähnlichen Multi-Service-Stack und fragst dich, wie du Routing und TLS sauber löst? Lass uns das gemeinsam einschätzen.