· David Göschel · Architektur · 4 minuten Lesezeit
Warum mein Chunking trotz Tokenisierung noch scheiterte
Ich hatte die Textaufteilung bereits eingebaut und sah trotzdem weiter den Kontextfehler. Erst als ich den Tokenrahmen und die Spezialtoken mitgedacht habe, wurde die Ursache sichtbar.

Inhalt
- Der Fehler blieb trotz Chunking sichtbar
- Warum 512 Token nicht die ganze Wahrheit sind
- Was ich daraus ableite
- Alle Artikel der Serie
Der Fehler blieb trotz Chunking sichtbar
Ich hatte den Ingest-Worker bereits so umgebaut, dass er lange Texte in mehrere Token-Chunks aufteilt. Im Log sah ich deshalb etwas, das zunächst gut aussah:
// Old worker log showing tight chunk sizes with no safety margin
[IngestWorker] captureId abc | Original tokens: 828 | Chunks: 2 | ChunkSize: 512 | Overlap: 64Trotzdem kam der gefürchtete Kontext-Überlauffehler des Embedding-Providers weiter zurück. Genau das ist der Punkt, an dem ich aufhören musste, nur auf die grobe Chunk-Anzahl im Code zu vertrauen. Eine theoretische Zahl im Log ist noch kein Beweis dafür, dass der Vektordatenbank-Provider oder das lokale Embedding-Modell die Eingabe am Ende auch wirklich fehlerfrei akzeptieren.
Warum 512 Token nicht die ganze Wahrheit sind
Mein erster schwerer Denkfehler bei mxbai-embed-large war simpel: Ich habe die harte Modellgrenze von 512 Tokens direkt als maximale Chunkgröße im Code verwendet. Das wirkt auf den ersten Blick logisch, ist in der Realität jedoch viel zu knapp kalkuliert. Ein Modell ergänzt bei der Verarbeitung intern oft Spezialtoken (wie <s> und </s> für Anfang und Ende des Textes). Zudem zählt ein einfacher externer Tokenzähler Wörter oft anders, als es die interne Tokenisierungs-Pipeline des Embedding-Modells tut.
Wenn man also einen Text exakt auf 512 Tokens schneidet, rutscht der eigentliche API-Request durch diese Abweichungen und die zusätzlichen Spezialtoken unweigerlich über die harte Kante des Context Windows. Das Ergebnis: Man hat formal im Worker sauber segmentiert, praktisch aber keinen Millimeter Sicherheitsabstand gelassen.
Das war die entscheidende Diagnose. Nicht das Prinzip des Chunkings war falsch, sondern die naive Annahme, dass die maximale Modellgrenze zugleich die sichere, nutzbare Arbeitsgröße im Ingest-Prozess is.
Was ich daraus ableite
Wir dürfen die maximale Modellgrenze niemals als Zielwert anvisieren, sondern müssen sie als absolute, unantastbare Oberkante betrachten. Für stabile Embeddings ist ein bewusster Puffer zwingend notwendig. Nur so bleibt der Worker auch dann stabil, wenn der Tokenizer des Modells Spezialtoken injiziert oder leichte Differenzen beim Re-Encoding auftreten.
Diese Diagnose war die Initialzündung für zwei fundamentale Architektur-Entscheidungen in unserem Memory-Engine-Monorepo:
- Modell-Upgrade auf
bge-m3: Ein leistungsfähigeres, multilinguales Modell mit einem weitaus größeren Context-Fenster von 8192 Tokens. - Konservatives Token-Budget: Die Festlegung einer kontrollierten Chunk-Größe von 1500 Tokens, die weit unter dem Maximum bleibt, um die semantische Fokussierung zu maximieren und jegliches Risiko von Überläufen auszuschließen.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
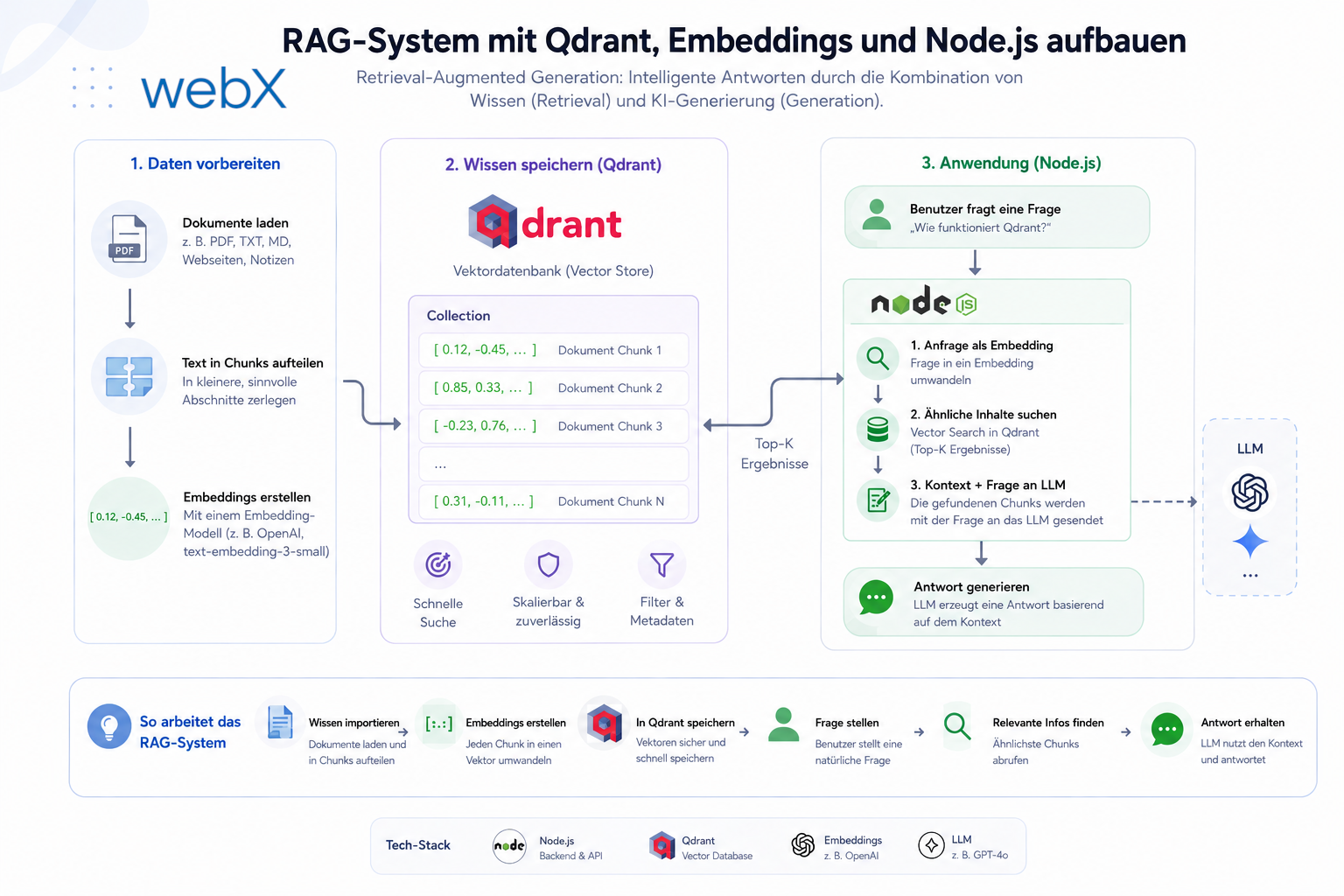
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: (dieser Artikel)
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
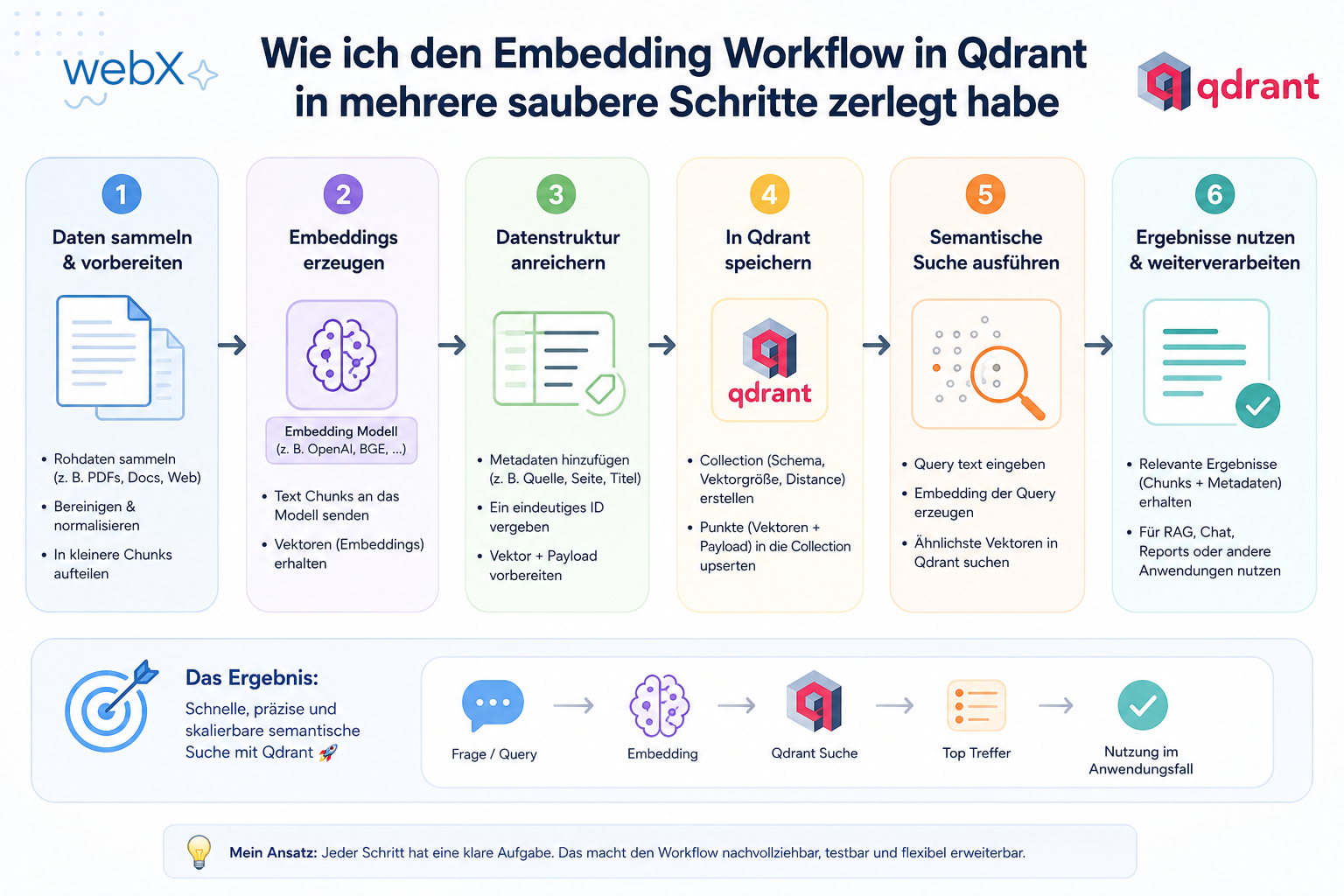
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du arbeitest gerade an einem ähnlichen RAG System und willst die gleiche Struktur für dein Projekt bewerten? Lass uns das gemeinsam einschätzen.