· David Göschel · Architektur · 8 minuten Lesezeit
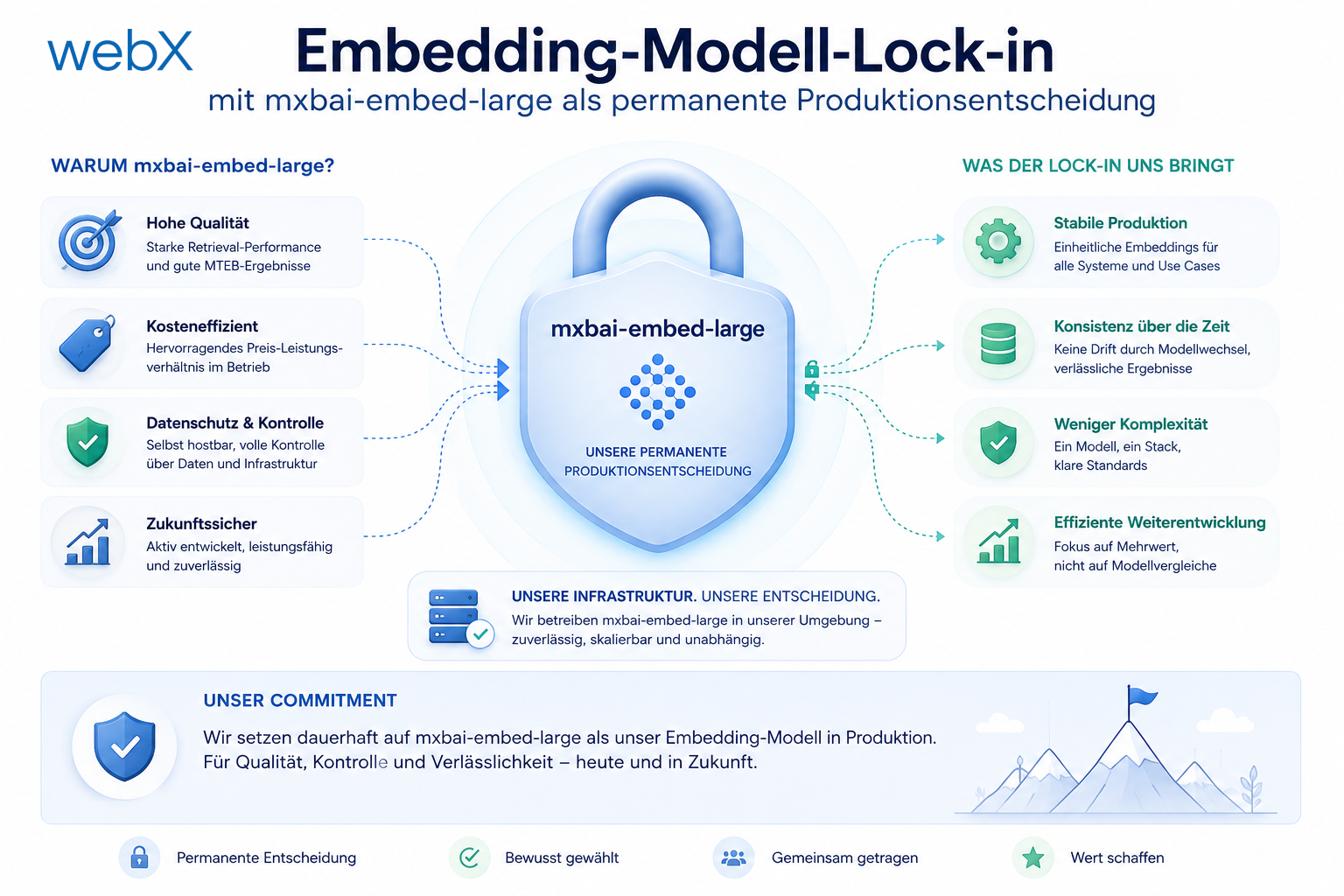
Embedding-Modell-Lock-in mit mxbai-embed-large als permanente Produktionsentscheidung
Ich behandle die Wahl des Embedding-Modells nicht als austauschbare Umgebungsvariable. In Qdrant schreibt sie sich direkt in jede Collection ein. Wer lokal und in Produktion auf unterschiedliche Vektorräume setzt, baut sich eine teure Migration in die Zukunft ein.
Inhalt
- Das Problem mit dem Embedding-Modell
- 768 oder 1024 Dimensionen?
- Warum dasselbe Modell lokal und in Produktion
- Die Entscheidung für mxbai-embed-large
- VECTOR_SIZE ist immutable
- embeddingModelVersion im Payload
- Lokale Entwicklung und der Modell-Download
- Alle Artikel der Serie
Das Problem mit dem Embedding-Modell
Ich habe am Anfang selbst fast denselben Denkfehler gemacht wie viele Teams beim ersten RAG-System: Das Embedding-Modell sieht in der Konfiguration wie eine austauschbare Umgebungsvariable aus. In Wirklichkeit ist es eine Schema-Entscheidung.
Sobald ich den ersten Vektor in Qdrant schreibe, lege ich einen konkreten Vektorraum fest. Dieser Raum gehört nicht nur zur Dimension, sondern auch zur Geometrie des Modells. Wenn ich also heute Modell X benutze und morgen Modell Y, dann ändern sich nicht nur Zahlenwerte, sondern die semantische Bedeutung jedes einzelnen Koordinatenpunkts.
Genau deshalb ist ein späterer Wechsel kein kleiner Eingriff. Wenn ich auf ein anderes Embedding-Modell umstelle, muss ich alle vorhandenen Texte neu einbetten. Das gilt auch dann, wenn beide Modelle zufällig dieselbe Vektorgröße ausgeben. Zwei 1024-dimensionale Modelle teilen sich nicht automatisch denselben Raum. Mischbetrieb würde die Suche still verschlechtern. Genau das ist gefährlich, weil der Fehler nicht als Crash sichtbar wird, sondern als langsam schlechter werdende Relevanz.
768 oder 1024 Dimensionen?
Für meinen Fall sind die Inhalte meistens kurz: Instagram Captions, Notizen, Tags, manchmal Alt-Text. Das liegt oft grob zwischen 50 und 300 Tokens. Rein technisch reichen dafür 768 Dimensionen sehr oft aus. nomic-embed-text ist deshalb kein schlechtes Modell.
Trotzdem ist 1024 für mich die robustere Produktionsentscheidung. Der Zugewinn liegt nicht in magischer Qualität, sondern in besserer semantischer Trennschärfe, sobald die Texte etwas länger, dichter oder sprachlich unordentlicher werden. Gerade bei gemischten Inhalten aus Caption, Nutzer-Notiz und Metadaten will ich lieber etwas mehr Raum als zu wenig.
mxbai-embed-large ist dafür ein sehr guter Kandidat. Das Modell taucht in offenen Benchmarks wie MTEB seit Langem weit vorne auf und ist unter den frei lokal nutzbaren Embedding-Modellen konstant stark. Gleichzeitig bleibt die Vektorgröße bei 1024 und damit noch in einem Bereich, der für Qdrant und typische RAG-Workloads sehr gut handhabbar ist.
1536 Dimensionen, etwa beim OpenAI-Standard für text-embedding-3-small, sind ebenfalls möglich. Ich sehe dafür in diesem Projekt aber keinen zwingenden Mehrwert. Für kurze Inhalte ist der Sprung von 1024 auf 1536 kleiner als der operative Nachteil, später ein anderes Produktionsmodell einbauen zu wollen.
Der eigentliche Punkt ist also nicht nur Qualität. Der eigentliche Punkt ist Kompatibilität. mxbai-embed-large hat dieselbe Größenklasse wie ein späteres Cloud-Modell wie mistral-embed, das ebenfalls 1024 Dimensionen nutzt. Damit bleibt lokal erzeugter Vektorbestand mit einer späteren Produktionsstrategie kompatibel.
Warum dasselbe Modell lokal und in Produktion
Genau hier entsteht der eigentliche Lock-in. Wenn ich lokal mit nomic-embed-text arbeite und in Produktion mit mistral-embed, dann existieren faktisch zwei getrennte Welten. Beide können Qdrant füllen, aber ihre Collections sind nicht kompatibel.
Im aktuellen Backend sehe ich direkt, wie früh diese Entscheidung greift:
// backend/src/services/providers/ollama-provider.ts
constructor() {
this.client = new Ollama({
host: process.env.OLLAMA_URL || "http://localhost:11434",
});
this.embeddingModel = process.env.EMBEDDING_MODEL || "nomic-embed-text";
this.generationModel = process.env.GENERATION_MODEL || "llama3.2";
}Das Modell wird beim Provider festgelegt, der Worker erzeugt daraus Embeddings und speichert sie direkt in Qdrant. Es gibt keinen neutralen Zwischenzustand. Wenn ich lokal mit einem anderen Modell schreibe als später in Produktion, muss ich beim Umstieg jede bereits gespeicherte Nutzerdatenbasis noch einmal durch das neue Modell schicken.
Die Größenordnung kippt sehr schnell. 1000 Nutzer mit jeweils 500 Captures bedeuten 500000 Re-Embeddings. Mit einer Cloud API sind das 500000 zusätzliche Aufrufe, die keinen neuen Geschäftswert erzeugen. Ich zahle nur dafür, eine frühe Modellinkonsistenz zu reparieren.
Genau diesen Migrationsjob will ich nie bauen müssen. Dasselbe Modell lokal und in Produktion eliminiert die gesamte Klasse dieses Problems.
Die Entscheidung für mxbai-embed-large
Für mich ist die sauberste Entscheidung deshalb, die Konfiguration früh auf 1024 festzuziehen und lokal wie später in Produktion denselben Embedding-Pfad zu fahren.
# docker-compose.yml
environment:
- EMBEDDING_MODEL=mxbai-embed-large
- VECTOR_SIZE=1024Das ist mehr als eine bequeme Standardeinstellung. VECTOR_SIZE=1024 wird damit zu einer Produktionskonstante. Ich würde diese Zahl genauso behandeln wie ein Datenbankschema: dokumentiert, bewusst gewählt und nach dem ersten produktiven Write nicht mehr still verändert.
In der Beispielkonfiguration würde ich das auch genau so benennen:
# VECTOR_SIZE is immutable after the first write to Qdrant.
# Changing this value requires recreating every user collection
# and re-embedding all stored data.
VECTOR_SIZE=1024Damit ist für jeden sofort sichtbar, dass hier keine harmlose Optimierung steckt, sondern eine irreversible Infrastrukturentscheidung.
VECTOR_SIZE ist immutable
Warum ich dieses Wort so hart wähle, zeigt der eigentliche Qdrant-Code:
// backend/src/services/qdrant.ts
const VECTOR_SIZE = parseInt(process.env.VECTOR_SIZE ?? '768', 10);
export async function ensureCollection(userId: string): Promise<void> {
const name = getCollectionName(userId);
try {
await client.getCollection(name);
} catch {
await client.createCollection(name, {
vectors: { size: VECTOR_SIZE, distance: 'Cosine' },
});
}
}Die Collection bekommt ihre Vektorgröße genau beim Erstellen. Danach bleibt sie fest. Wenn ich später VECTOR_SIZE von 768 auf 1024 ändere, dann passiert nicht einfach ein stilles Upgrade. Bestehende Collections bleiben bei 768. Neue Collections entstehen mit 1024. Ab diesem Moment habe ich einen gemischten Bestand, der operativ kaum noch sauber zu verwalten ist.
Noch kritischer wird es beim Upsert. Ein 1024-dimensionaler Vektor passt nicht in eine 768er Collection. Dann bekomme ich zwar irgendwann einen Fehler, aber zu diesem Zeitpunkt ist die eigentliche Ursache schon viel früher entstanden: bei einer scheinbar harmlosen Änderung in der Umgebungsvariable.
Ich halte deshalb eine explizite Dokumentation für Pflicht. Wer VECTOR_SIZE ändert, muss wissen: Das ist ein Migrationsprojekt, keine Konfigurationspflege.
embeddingModelVersion im Payload
Selbst wenn ich mich heute sauber auf ein Modell festlege, will ich für einen späteren Notfall vorbereitet sein. Genau dafür würde ich ein kleines Metadatenfeld ergänzen: embeddingModelVersion: "mxbai-embed-large-v1".
Der aktuelle Payload-Typ kennt dieses Feld noch nicht:
// backend/src/types.ts
export type QdrantPayload =
| (Omit<InstagramAnalysisPayload, 'image'> & {
image: StoredImage;
embeddingText: string;
})
| (Omit<GenericWebPagePayload, 'image'> & {
image: StoredImage;
embeddingText: string;
});Ich würde genau dort die Modellversion mit abspeichern. Der Preis ist minimal: ein einziges zusätzliches Feld pro Punkt. Der Nutzen ist im Ernstfall groß. Wenn ich irgendwann doch migrieren muss, kann ich sofort filtern, welche Punkte noch mit mxbai-embed-large-v1 geschrieben wurden und welche schon mit einer späteren Generation stammen.
Migrationen werden dadurch nicht billig. Sie werden aber steuerbar.
Lokale Entwicklung und der Modell-Download
Praktisch bedeutet die Entscheidung für mxbai-embed-large zuerst nur einen etwas größeren Download:
# Pull the embedding model once into the local Ollama store
ollama pull mxbai-embed-largeDas Modell liegt bei ungefähr 670 MB. nomic-embed-text liegt eher bei rund 274 MB. Dieser Unterschied ist real, aber er fällt genau einmal an. Danach liegt das Modell lokal auf der Platte und ist bei jedem Neustart sofort wieder verfügbar.
Wenn ich den automatischen Pull im Container beibehalte, würde ich auch dort denselben Namen eintragen:
# ollama/entrypoint.sh
MODELS=("mxbai-embed-large" "llama3.2")Für mich ist das ein sehr guter Tausch. Ich bezahle einmalig etwas mehr Download, spare mir dafür aber im besten Fall eine komplette Re-Embedding-Migration, sobald lokal und Produktion zusammenwachsen.
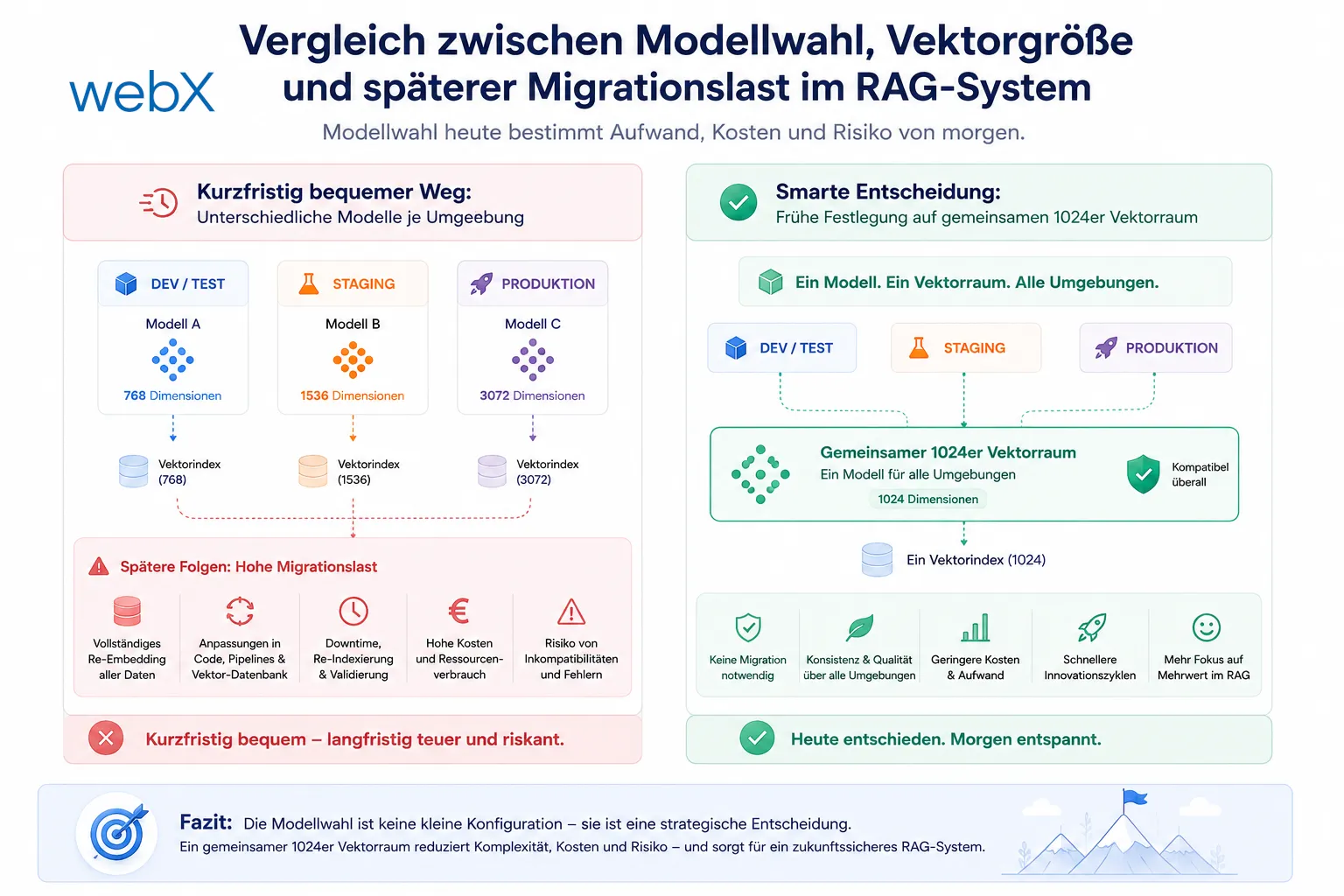
Die Grafik zeigt, warum ich die Modellwahl nicht als kleine Konfiguration sehe. Links steht der kurzfristig bequeme Weg mit unterschiedlichen Modellen je Umgebung. Rechts steht die frühe Festlegung auf einen gemeinsamen 1024er Vektorraum, der spätere Migrationen vermeidet.
Ich will das Embedding-Modell deshalb möglichst früh als Infrastrukturvertrag behandeln. Nicht weil jede spätere Änderung unmöglich wäre, sondern weil sie ab dem ersten gespeicherten Nutzerdatensatz teuer, langsam und riskant wird.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: (dieser Artikel)
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du baust gerade ein ähnliches System und überlegst, welche Entscheidungen für dein Projekt passen? Lass uns das gemeinsam einschätzen.