· David Göschel · DevOps · 7 minuten Lesezeit
Warum ein manueller docker exec zum automatisierten Ollama Entrypoint-Setup führte
Nach dem ersten erfolgreichen Start meines RAG-Systems dachte ich: fertig. Dann habe ich einen docker exec-Schritt im Quick Start gesehen und nicht schlafen können. Hier ist wie ein kleines Reibungsmoment zu einer besseren Architektur geführt hat.
Inhalt
- Der Quick Start, der mich gestört hat
- Was ist eigentlich das Problem?
- Der Entrypoint als Initialisierungsort
- Das entrypoint.sh Script
- Idempotenz
- Das Ergebnis in der docker-compose.override.yml
- Was dieser Moment über Developer Experience aussagt
- Das Prinzip dahinter
- Alle Artikel der Serie
Der Quick Start, der mich gestört hat
Das System lief. Docker Compose hochgefahren. Backend verbunden. Chrome Extension schickt Metadaten, Qdrant speichert Embeddings. Erster Erfolg.
Dann habe ich die README von Copilot schreiben lassen und bin über diese Zeilen gestolpert:
# after first start: pull models manually
docker exec ollama_local ollama pull nomic-embed-text
docker exec ollama_local ollama pull llama3.2Copilot hat die Zeilen geschrieben. Ich hab sie committed.
Das ist der Moment, wo die meisten Entwickler weitermachen. Ich nicht.
Nicht weil ich pedantisch bin. Sondern weil ich dieses Projekt irgendwann der Öffentlichkeit übergeben will. Und weil jede zusätzliche Zeile im Quick Start ein Mensch ist, der das Projekt wieder schließt.
Was ist eigentlich das Problem?
Auf der Oberfläche: Zwei extra Befehle nach dem Start.
Darunter: Ein fundamentaler Bruch im mentalen Modell.
docker-compose up heißt: Das System ist bereit. Fertig. Jetzt funktioniert es.
Wenn danach noch manuelle Schritte notwendig sind (Models pullen, Services neu starten, Config anpassen), dann lügt der erste Befehl. Das System ist nicht bereit. Es ist halbfertig gestartet und wartet darauf, dass der Entwickler den Rest erledigt.
Das ist technische Schulden. Nicht in Form von schlechtem Code, sondern in Form von implizitem Wissen, das nirgendwo dokumentiert ist außer im Quick Start den niemand vollständig liest.
Der Entrypoint als Initialisierungsort
Die Lösung war eigentlich offensichtlich, nachdem ich aufgehört hatte, das Problem falsch zu denken.
Docker-Container haben Entrypoints. Entrypoints laufen beim Start. Wenn Initialisierungslogik beim Start laufen soll, warum nicht dort?
Ich habe ein eigenes ollama/Dockerfile erstellt:
FROM ollama/ollama:latest
RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/*
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]Das offizielle ollama/ollama:latest-Image hat kein curl. Ohne curl ist kein Warten auf die API möglich. Also wird curl installiert. Drei Zeilen.
Das entrypoint.sh Script
#!/bin/bash
set -e
MODELS=("nomic-embed-text" "llama3.2")
# start server in background
ollama serve &
OLLAMA_PID=$!
# wait for API
echo "Waiting for Ollama API..."
until curl -sf http://localhost:11434/api/tags > /dev/null 2>&1; do
sleep 1
done
echo "Ollama API ready."
# idempotently pull models
for model in "${MODELS[@]}"; do
if ollama show "$model" > /dev/null 2>&1; then
echo "Model '$model' already present. Skipping."
else
echo "Pulling model '$model'..."
ollama pull "$model"
echo "Model '$model' pulled successfully."
fi
done
# keep main process alive
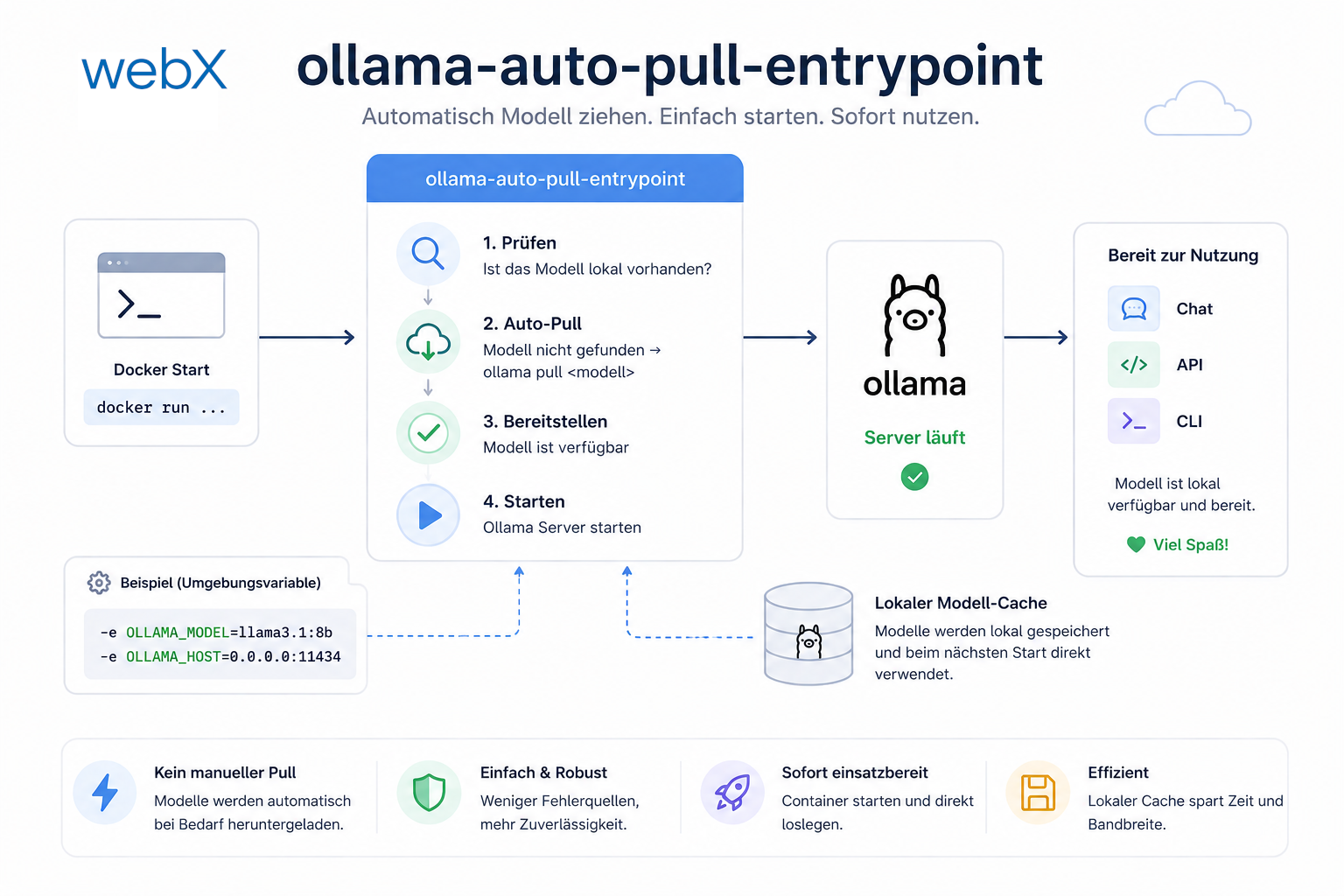
wait $OLLAMA_PIDDas Script ist in drei Teile gegliedert. Jeder Teil löst ein spezifisches Problem.
Teil 1: Server im Hintergrund starten. ollama serve & - das & ist entscheidend. Ohne es blockiert der Prozess und das Script kommt nie zu den Modellen. Den PID speichern: OLLAMA_PID=$!. Der wird am Ende gebraucht.
Teil 2: Auf die API warten. Ollama braucht eine Sekunde zum Hochfahren. Wird sofort ollama pull ausgeführt, ist die API noch nicht ready und der Befehl schlägt fehl. Die until-Schleife fragt jede Sekunde nach, ob /api/tags antwortet. Erst dann geht es weiter.
Teil 3: Modelle idempotent prüfen. ollama show "$model" gibt Exit-Code 0 zurück wenn das Modell vorhanden ist, nicht-null wenn nicht. Kein pull wenn nicht nötig. Beim zweiten Start, wenn die Modelle im Volume liegen, überspringt der Loop alles. Start in Sekunden, nicht Minuten.
Und dann: wait $OLLAMA_PID. Wenn das Script hier endet, endet der Container. wait hält den Container am Leben, solange ollama serve läuft. Und es leitet Signale korrekt weiter: docker stop funktioniert sauber.
Idempotenz
Der Begriff klingt sperrig. Was er bedeutet ist simpel: Der gleiche Befehl mehrmals ausführen hat dieselbe Wirkung wie einmal.
Beim ersten Start: Modelle nicht vorhanden, Download. Beim zweiten Start: Modelle vorhanden, Skip. Nach docker-compose down ohne -v: Modelle im Volume, Skip. Nach docker-compose down -v: Volume gelöscht, Download.
Das ist das erwartete Verhalten. Kein “oh ich hab vergessen zu pullen”. Kein “warum lädt das nochmal herunter”. Das System weiß was es hat und reagiert darauf.
Das Ergebnis in der docker-compose.override.yml
Statt:
ollama:
image: ollama/ollama:latestJetzt:
ollama:
build: ./ollamaEine Zeile Änderung. Ein komplett anderes Verhalten beim Start.
Die Komplexität steckt im Container, nicht in der Dokumentation.
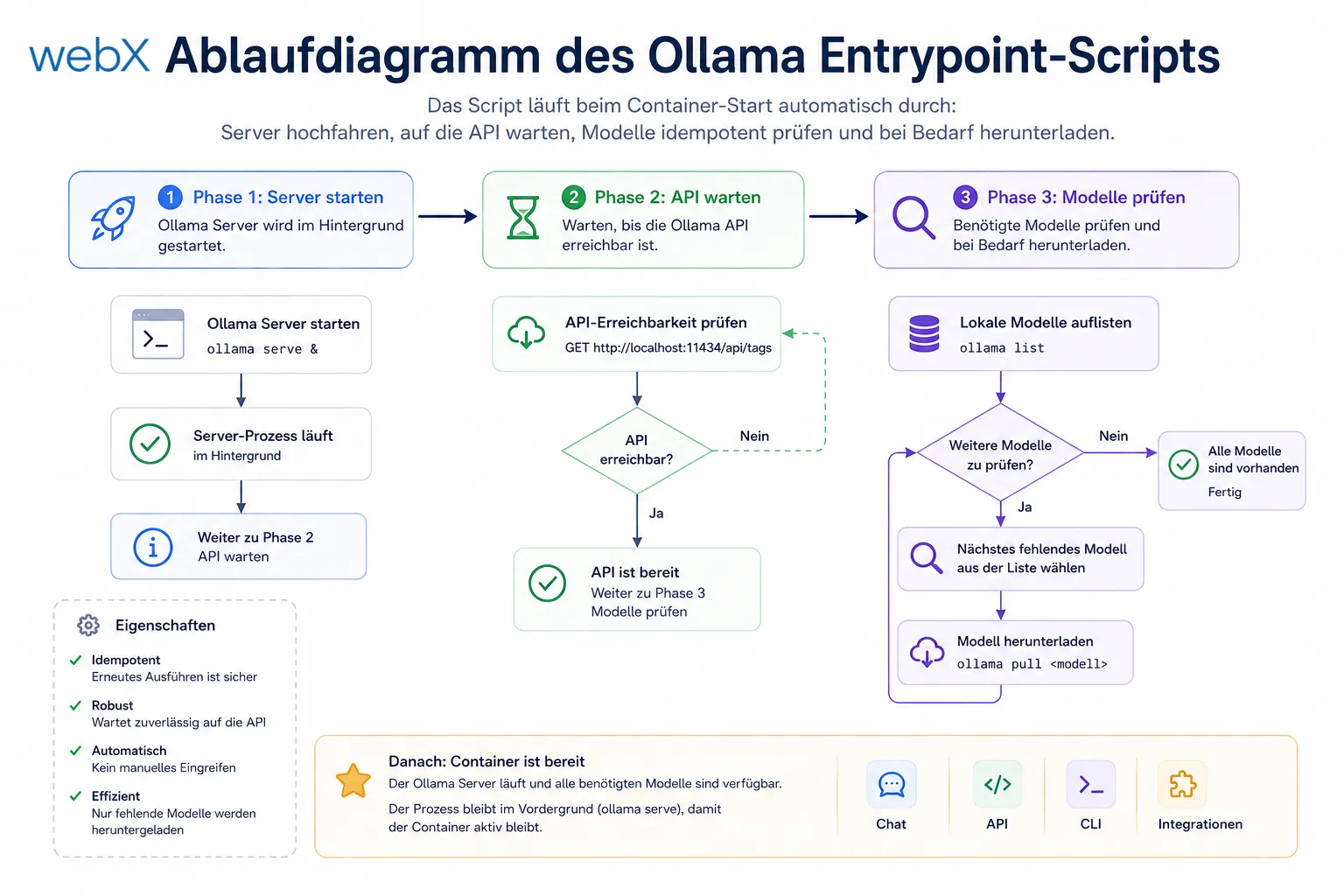 Abbildung: Das Script läuft beim Container-Start automatisch durch: Server hochfahren, auf die API warten, Modelle idempotent prüfen und bei Bedarf herunterladen.
Abbildung: Das Script läuft beim Container-Start automatisch durch: Server hochfahren, auf die API warten, Modelle idempotent prüfen und bei Bedarf herunterladen.
Was dieser Moment über Developer Experience aussagt
Es gibt einen Begriff in der Produktentwicklung: Time to Value. Die Zeit vom ersten Kontakt bis zum ersten “Aha, das funktioniert!”-Moment.
Bei Developer Tools ist das Time to First docker-compose up.
Jede Zeile in einem Quick Start, die nach up kommt, verlängert die Time to Value. Jeder manuelle Schritt ist eine Hürde. Nicht weil Entwickler zu faul sind, sondern weil Hürden akkumulieren. Zwei extra Befehle plus ein Neustart plus eine unklare Fehlermeldung macht aus einem fünfminütigen Setup ein dreißigminütiges Rätsel.
Ich baue dieses System für mich. Aber ich baue es als ob ich es für andere baue. Weil “ich” in drei Monaten auch jemand ist, der nicht mehr weiß was er sich gedacht hat.
Das Prinzip dahinter
Mache das Richtige einfach und das Falsche schwer.
In diesem Fall: Das Richtige ist, dass das System beim ersten docker-compose up --build vollständig läuft. Das Falsche ist, nach dem Start noch manuell eingreifen zu müssen.
Indem ich die Initialisierungslogik in den Container verlagere, wird das Richtige automatisch. Kein Entwickler kann vergessen, die Modelle zu pullen, weil es keinen Schritt zum Vergessen gibt.
Das ist keine Über-Ingenieurskunst. Das ist Respekt für die Zeit anderer Menschen.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
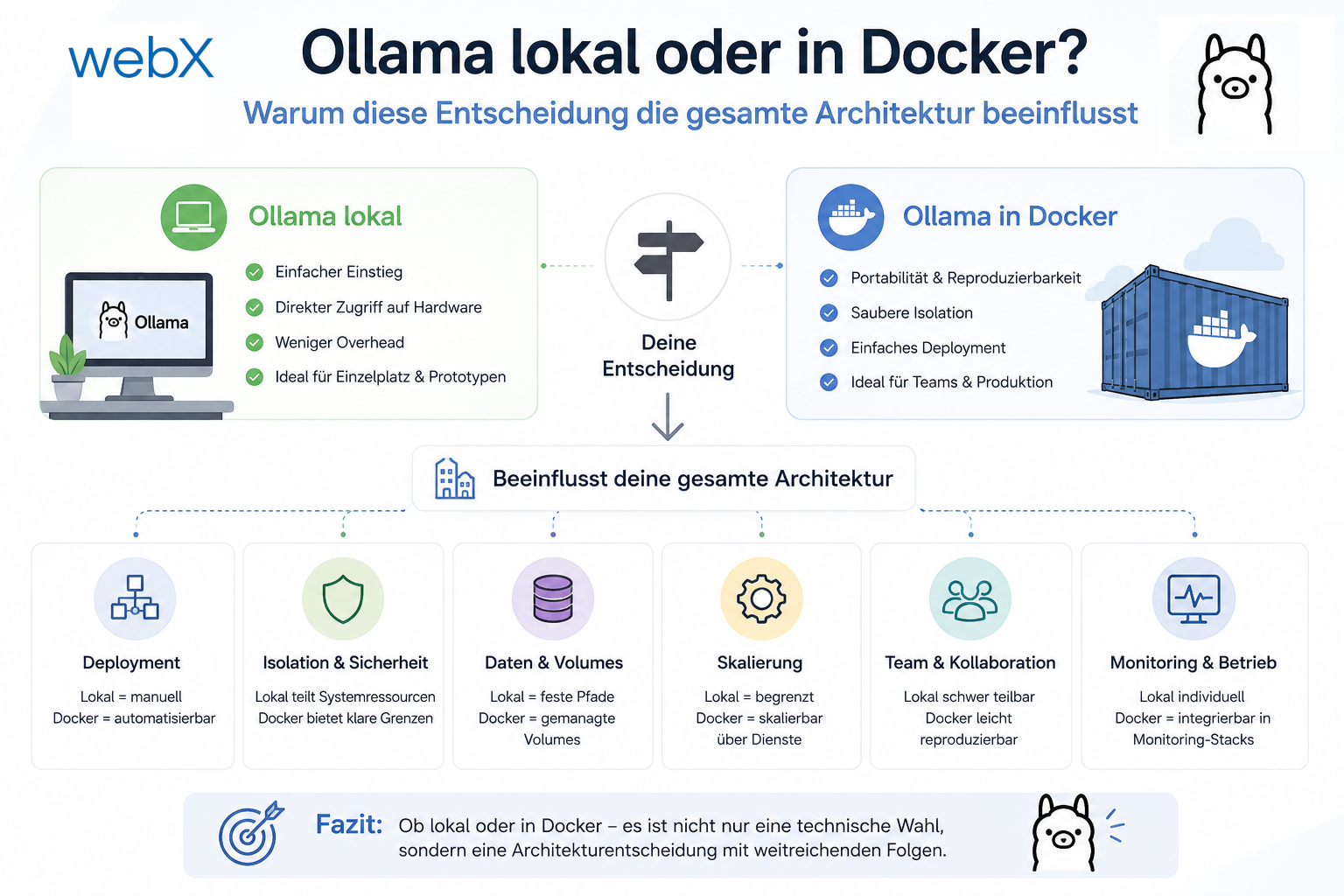
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: (dieser Artikel)
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
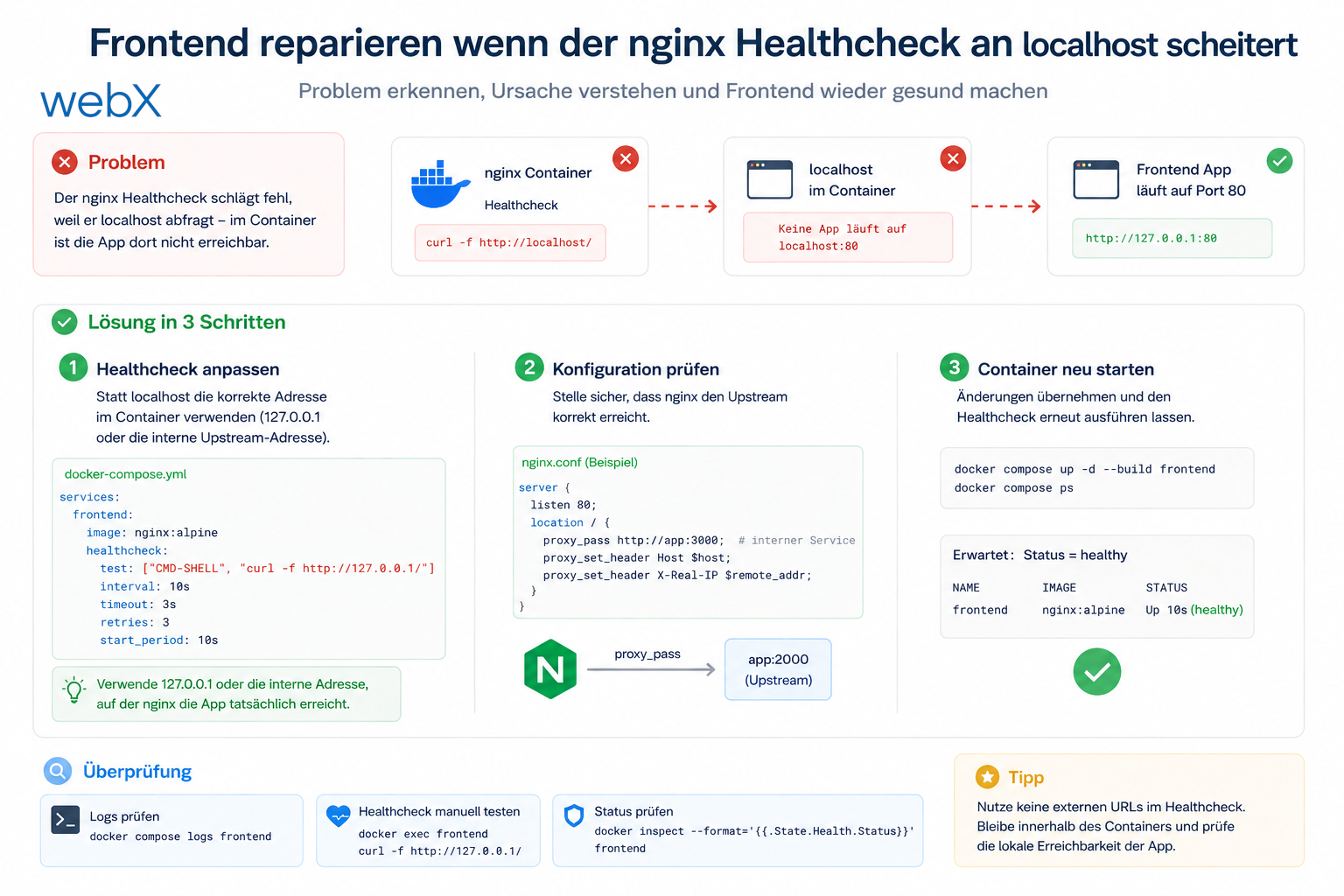
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
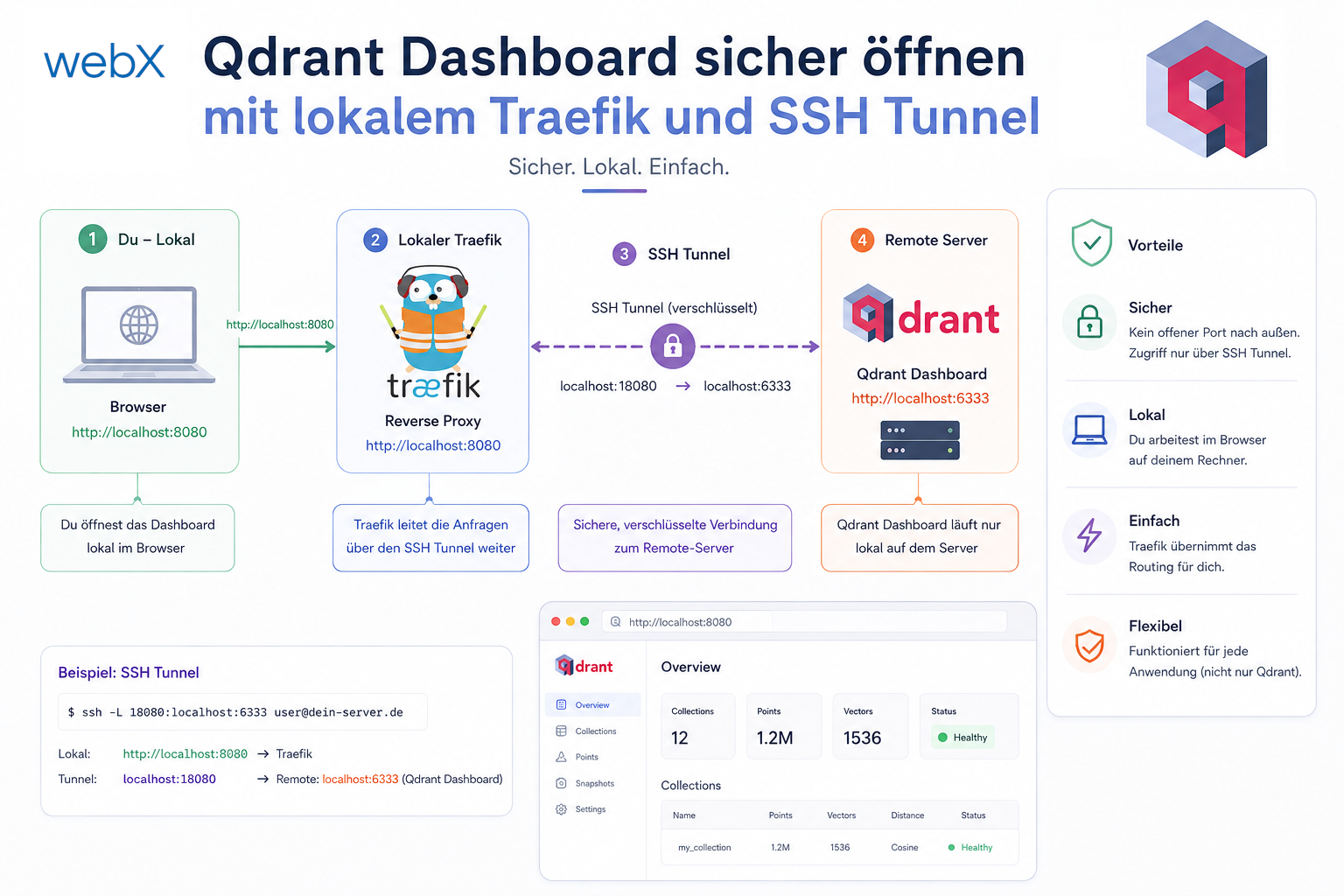
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du baust ein System mit lokaler KI-Inferenz und willst den Setup-Aufwand für neue Entwickler minimieren? Lass uns das gemeinsam einschätzen.