· David Göschel · DevOps · 7 minuten Lesezeit
Ollama lokal oder in Docker? Warum diese Entscheidung die gesamte Architektur beeinflusst
Als ich den Fehler "Ollama is not reachable" bekam, stand ich vor einer echten Architekturentscheidung: Ollama auf dem Host installieren oder als Docker-Container? Die Antwort hat meine gesamte Deployment-Strategie verändert.
Inhalt
- Der Moment, der alles in Frage gestellt hat
- Die zwei Optionen im Vergleich
- Warum die Frage eigentlich falsch gestellt ist
- Die Konsequenz
- Der erste Start
- Was diese Entscheidung in der Praxis bedeutet
- Die GPU-Frage für später
- Alle Artikel der Serie
Der Moment, der alles in Frage gestellt hat
Ich hatte das Backend fertig. Qdrant lief. Die Extension schickte Payloads. Und dann:
Fehler: Ollama is not reachable. Make sure Ollama is running on port 11434.Der erste Impuls: Ollama installieren, starten, fertig.
Aber ich hab inne gehalten und die eigentlich wichtige Frage gestellt:
Was ist der richtige Ort für Ollama, und was sagt diese Entscheidung über das gesamte System aus?
Diese Frage hat mich länger beschäftigt als erwartet. Und das Ergebnis hat die gesamte Architektur beeinflusst.
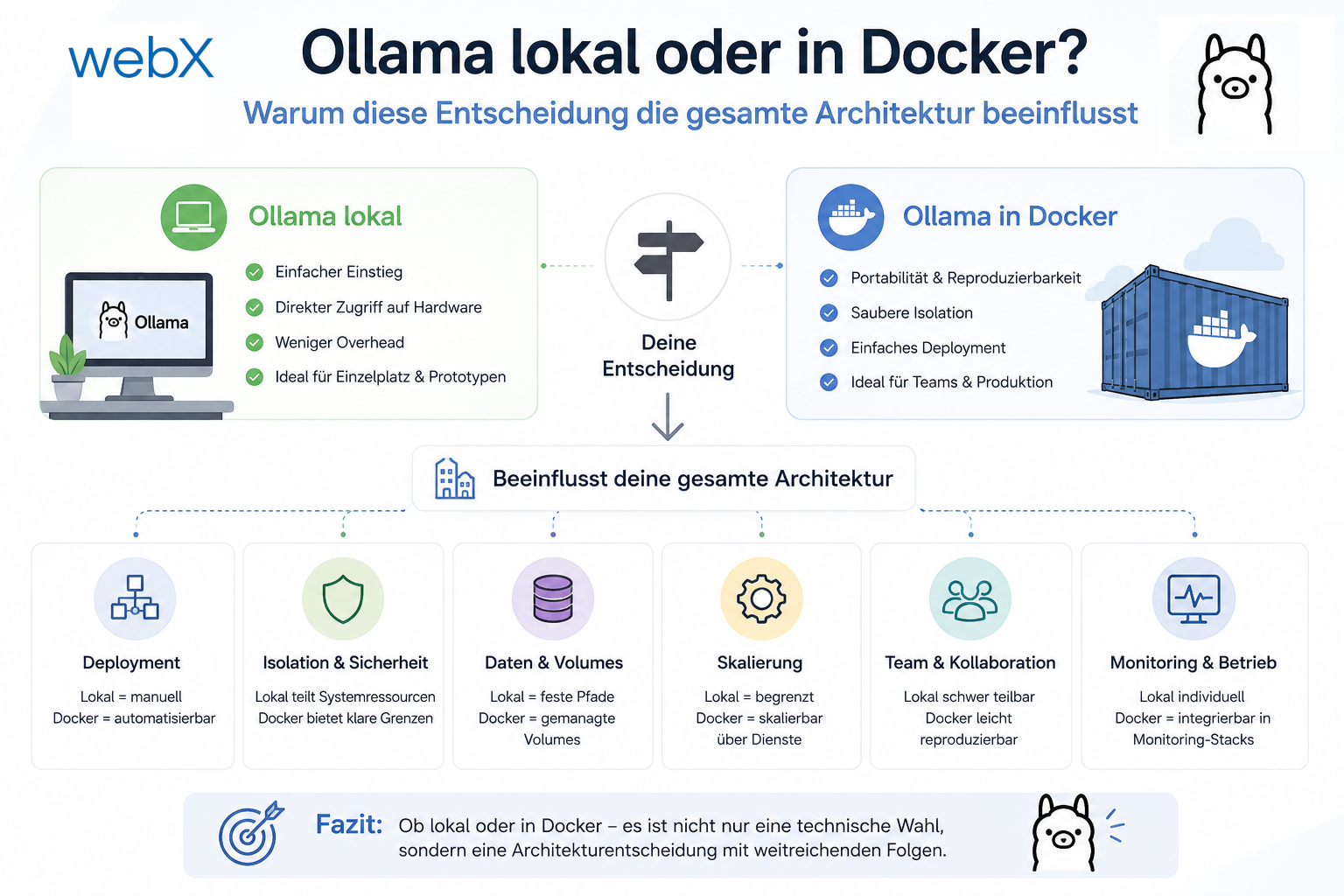
Die zwei Optionen im Vergleich
Ollama auf dem Host
curl -fsSL https://ollama.com/install.sh | sh
systemctl start ollama
ollama pull nomic-embed-text
ollama pull llama3.2Der Backend-Container in Docker verbindet sich dann via host.docker.internal:11434 oder 172.17.0.1:11434 mit dem Host.
Vorteile:
- GPU-Zugriff ohne Konfiguration: Ollama auf dem Host kann NVIDIA-GPUs direkt nutzen. In Docker braucht man das NVIDIA Container Toolkit und explizite GPU-Passthrough-Konfiguration
- Weniger Docker-Overhead: Keine Volumes für Modell-Daten, kein Container-Overhead für Inferenz
- Einfacheres erstes Setup: Drei Befehle, läuft sofort
Nachteile:
- System-Verschmutzung: Software auf dem Host bedeutet Updates verwalten, Systemd-Services, potenzielle Konflikte mit anderen Projekten
- Nicht portierbar: Ein neuer Mitarbeiter, ein neues System, eine CI/CD-Pipeline müssen alle Ollama separat installieren. Das Projekt ist nicht mehr
git clone && docker-compose up - Kein klarer Deployment-Pfad: In der Cloud gibt es keinen “Host”. Die Produktionsumgebung sieht fundamental anders aus als die Entwicklungsumgebung
Ollama in Docker
services:
ollama:
image: ollama/ollama:latest
volumes:
- ollama_data:/root/.ollama
# No host port mapping: backend communicates via the internal Docker network.
# Only enable if no local Ollama service is running on port 11434
# and Ollama needs to be reachable from the host:
# ports:
# - "11434:11434"Vorteile:
- Vollständige Reproduzierbarkeit:
docker-compose upstartet alles. Auf jedem System. Immer gleich. - Saubere Isolation: Ollama läuft in seiner eigenen Sandbox. Keine Auswirkungen auf den Host.
- Klarer Deployment-Pfad: Dieselbe
docker-compose.ymlbeschreibt lokal und (mit Overrides) die Cloud - GPU-Passthrough möglich: Mit NVIDIA Container Toolkit und einer einzigen
compose-Konfiguration
Nachteile:
- GPU-Setup ist aufwendiger: NVIDIA Container Toolkit muss auf dem Host installiert sein
- Etwas höherer Overhead: Container-Layer, Volume-Mounting für Modelle
- Port-Konflikt wenn Ollama bereits auf dem Host läuft: Docker versucht standardmäßig, den Host-Port 11434 zu exposen. Läuft bereits ein Ollama-Systemdienst, schlägt
docker-compose upmitaddress already in usefehl. Die Lösung: Dasports-Mapping weglassen, da das Backend ohnehin über das Docker-interne Netzwerk kommuniziert.
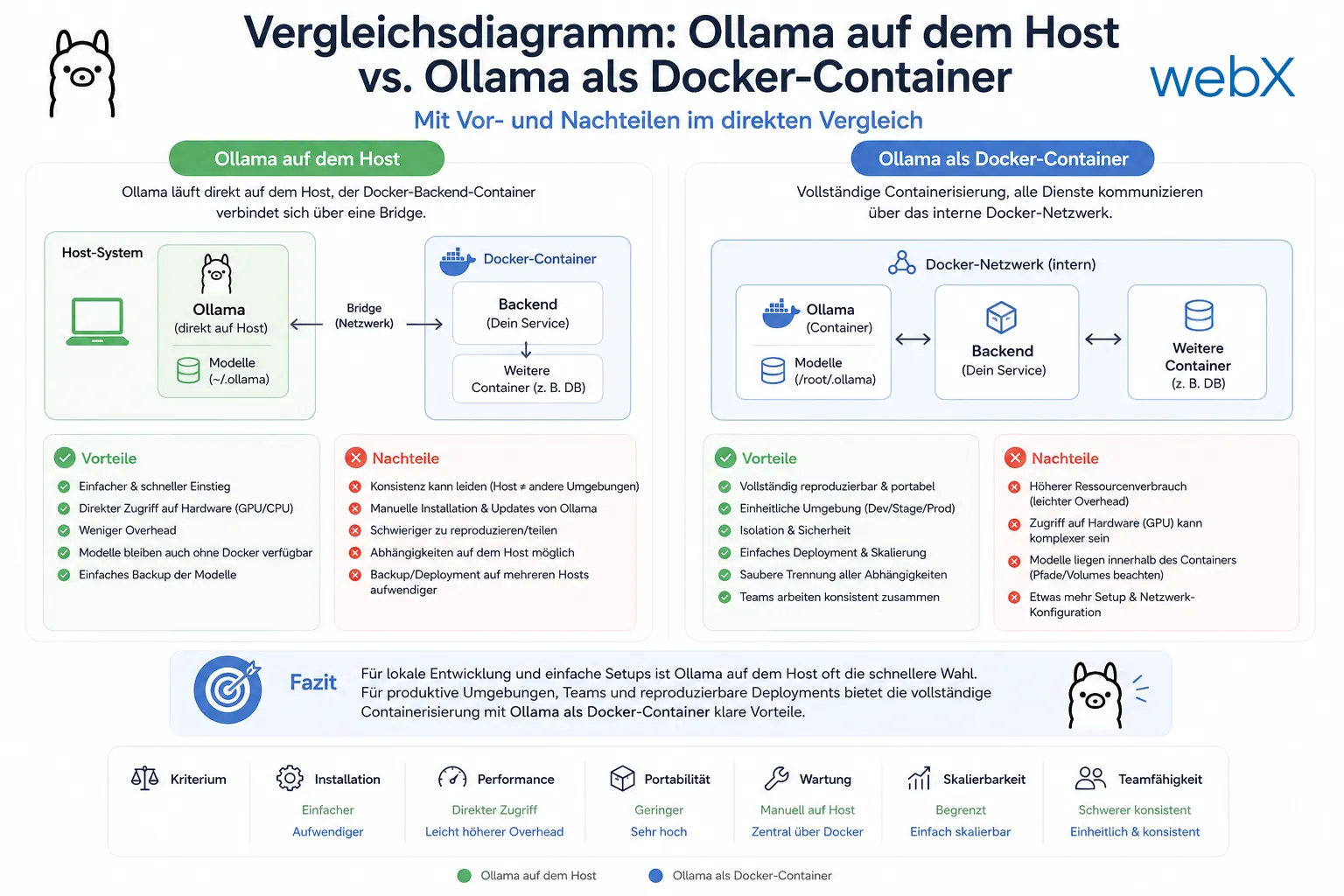 Abbildung: Links: Ollama läuft direkt auf dem Host, der Docker-Backend-Container verbindet sich über eine Bridge. Rechts: Vollständige Containerisierung, alle Dienste kommunizieren über das interne Docker-Netzwerk.
Abbildung: Links: Ollama läuft direkt auf dem Host, der Docker-Backend-Container verbindet sich über eine Bridge. Rechts: Vollständige Containerisierung, alle Dienste kommunizieren über das interne Docker-Netzwerk.
Warum die Frage eigentlich falsch gestellt ist
Ich habe gemerkt, dass ich die Frage “Ollama lokal oder Docker?” aus der falschen Perspektive betrachtet habe. Die eigentliche Frage ist:
Für wen baue ich dieses System?
Wenn die Antwort “nur für mich, auf dieser einen Maschine” ist, dann ist Host-Installation pragmatisch und ausreichend.
Wenn die Antwort “ich will das irgendwann deployen, teilen oder auf einem anderen System laufen lassen” ist, dann ist Host-Installation technische Schulden.
Ich baue ein System, das ich der Öffentlichkeit zugänglich machen möchte. Die Antwort war klar.
Die Konsequenz
Die Entscheidung für Docker hat eine Kaskade von weiteren Entscheidungen ausgelöst:
1. Provider-Abstraktion wird notwendig
Wenn Ollama in Docker läuft, ist das lokal perfekt. Aber in der Cloud? Einen GPU-optimierten Container für Ollama in Azure oder AWS zu betreiben ist teuer oder gar nicht verfügbar in der günstigsten Tier.
Also brauchte ich eine Abstraktion: Lokal läuft Ollama als Container, in der Cloud wird stattdessen OpenAI verwendet. Dieselbe Code-Basis, dieselbe Architektur, andere Implementierung. Das ist die Provider-Abstraktion, auf die das gesamte RAG-System aufbaut.
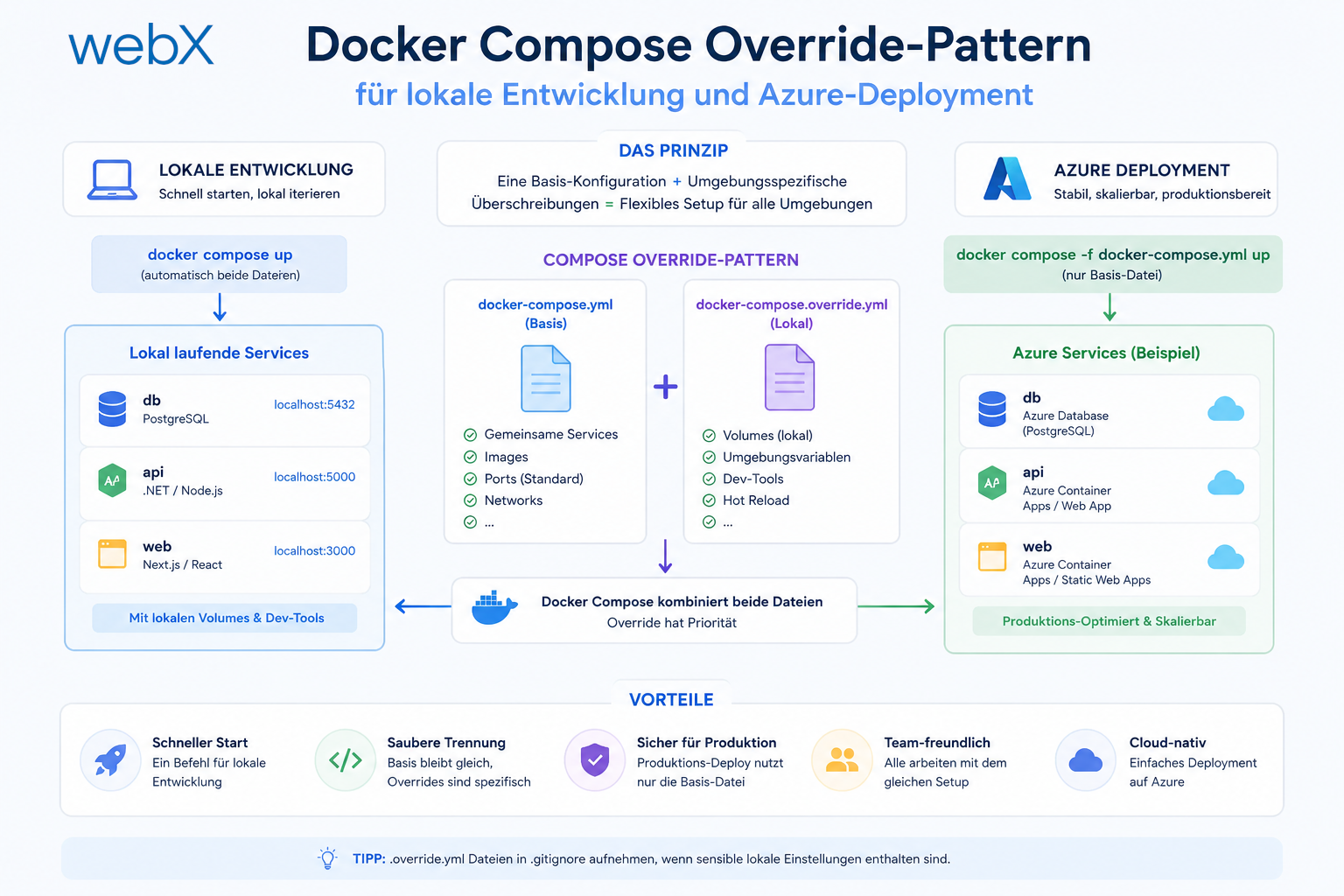
2. Docker Compose Override-Pattern
Wenn lokal Ollama dabei ist, in der Produktion aber nicht, wie manage ich das ohne zwei komplett verschiedene docker-compose.yml-Dateien?
Das Override-Pattern: Eine Basis-Datei, ein lokales Override (automatisch geladen), ein Produktions-Override (explizit angegeben). Drei Dateien, klare Verantwortlichkeiten.
3. Persistentes Volume für Modelle
Modelle sind groß. nomic-embed-text ist ~270MB, llama3.2 ist ~2GB. Die dürfen nicht bei jedem docker-compose down && docker-compose up neu heruntergeladen werden.
volumes:
ollama_data:
# Named volume: survives docker-compose down
# Deleted only with docker-compose down -v (explicit)Named Volumes in Docker persistieren über Container-Neustarts hinaus. Ohne -v-Flag beim down bleiben die Modell-Daten erhalten. Das ist das korrekte Verhalten.
Der erste Start
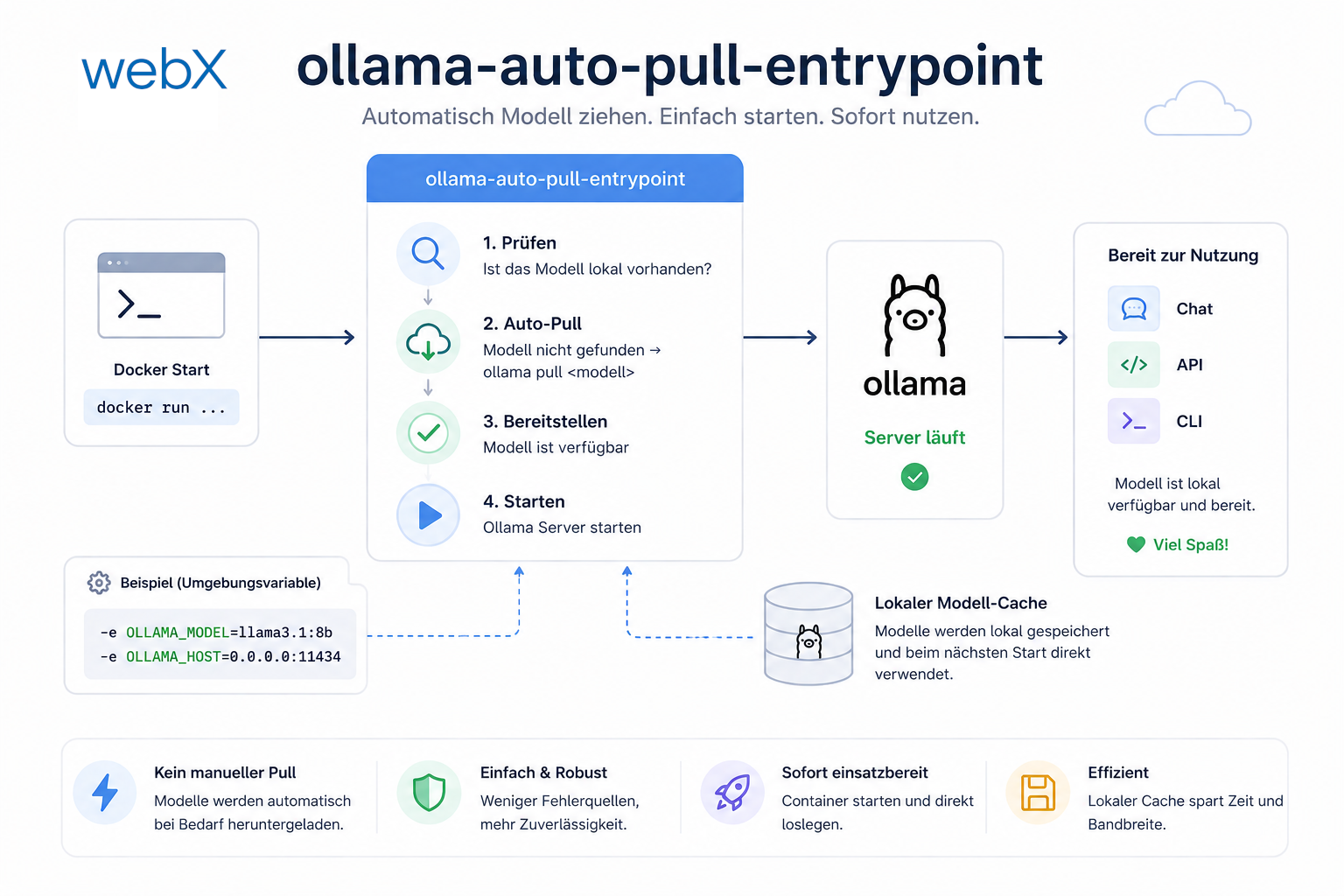
Wer das Projekt zum ersten Mal klont und startet:
docker-compose up --build -dFertig. Kein zweiter Schritt.
Der Ollama-Container lädt beim ersten Start automatisch nomic-embed-text (~274 MB) und llama3.2 (~2 GB) herunter. Das dauert einige Minuten, je nach Verbindung. Beim nächsten docker-compose up erkennt der Container die vorhandenen Modelle im Volume und startet sofort.
Das ermöglicht ein eigenes ollama/Dockerfile mit einem Entrypoint-Script, das diese Logik übernimmt: Server starten, auf API warten, Modelle prüfen, bei Bedarf pullen. Die Modelle persistieren in einem Named Volume.
Das Ergebnis: Wer das Repo klont, tippt einen Befehl. Alles läuft.
Was diese Entscheidung in der Praxis bedeutet
Diese Entscheidung hat mich etwa drei Stunden Mehraufwand gekostet. Dafür habe ich:
- Ein System, das auf jedem Rechner mit Docker funktioniert, ohne Setup-Dokumentation
- Eine klare Trennung zwischen lokaler Entwicklung und Produktion durch Override-Pattern
- Die Grundlage für eine Cloud-Deployment-Strategie, die nicht von Null anfangen muss
Wenn ich ein System für einen Kunden aufbaue und dann übergebe, will ich nicht, dass der nächste Entwickler eine stundenlange Setup-Doku durcharbeiten muss. docker-compose up sollte reichen.
Und wenn ich dasselbe System in die Cloud bringe, will ich nicht bei Null anfangen. Das Override-Pattern macht den Wechsel zu einer Frage von einem Flag.
Das ist keine Überentwicklung. Das ist die Grundlage für nachhaltige Softwareentwicklung.
Die GPU-Frage für später
Für alle mit NVIDIA-GPU: Docker und Ollama können GPU-Beschleunigung nutzen. Das Setup:
# Install NVIDIA Container Toolkit
sudo apt install nvidia-container-toolkit
sudo systemctl restart docker# docker-compose.override.yml
services:
ollama:
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]Das ist auskommentiert in meiner Override-Datei. Wer es nutzen will, aktiviert einen Block.
Für den produktiven Einsatz ohne GPU ist llama3.2 auf CPU langsamer, aber durchaus nutzbar für moderate Anfragemengen. nomic-embed-text (Embedding-Modell) ist auch auf CPU schnell genug.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: (dieser Artikel)
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du planst ein System mit lokaler KI-Inferenz und überlegst, wie du das sauber in Docker abbildest? Lass uns das gemeinsam einschätzen.