· David Göschel · DevOps · 7 minuten Lesezeit
Docker Compose Override-Pattern für lokale Entwicklung und Azure-Deployment
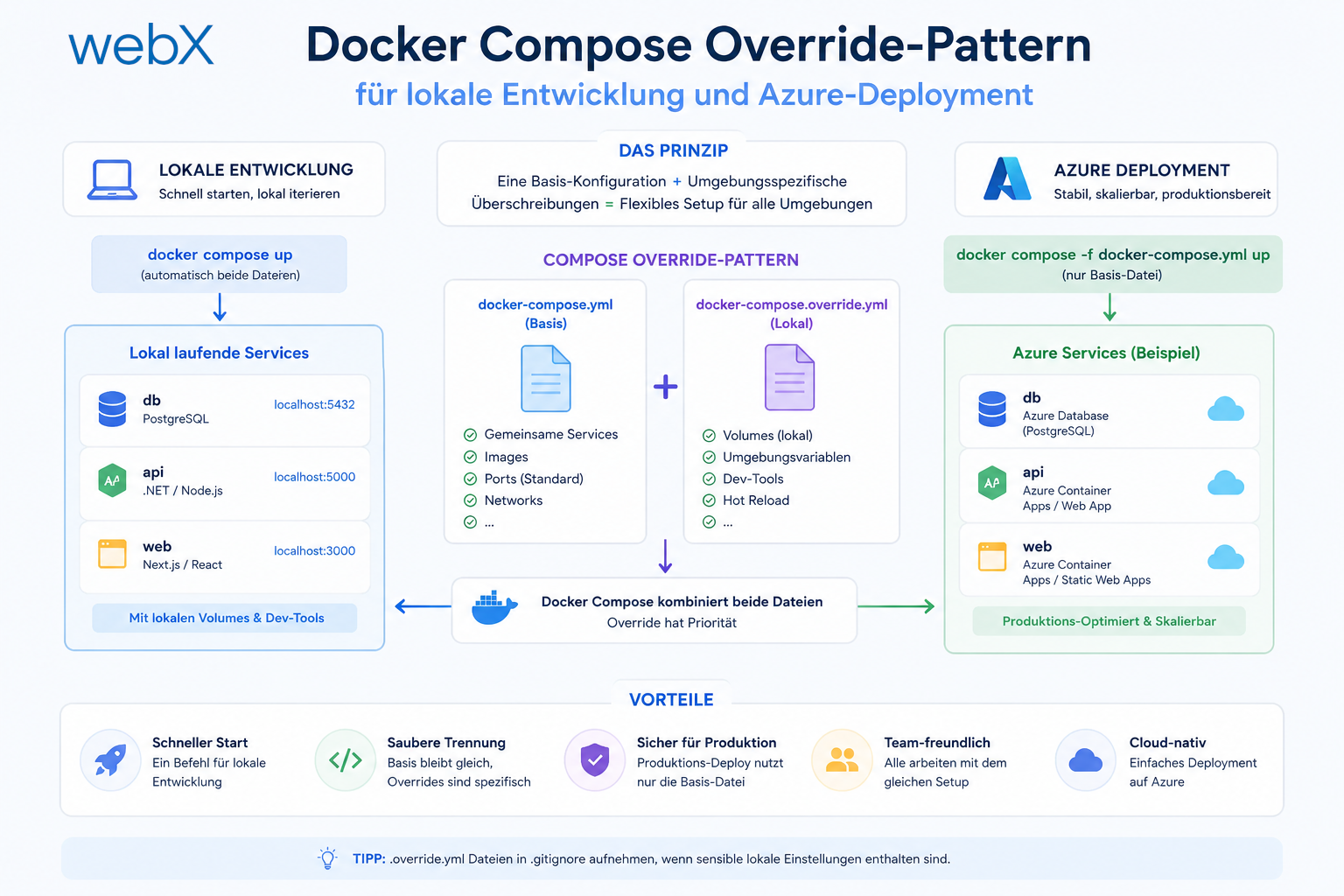
Die meisten Projekte haben ein docker-compose.yml für lokal und ein völlig anderes für die Cloud. Das führt zu Drift, Fehlern und "works on my machine"-Problemen. Ich zeige, wie das Docker Compose Override-Pattern beide Welten mit denselben Basis-Dateien verwaltet.
Inhalt
- Das Problem mit zwei docker-compose-Dateien
- Die Basis-Konfiguration
- Der lokale Override
- Der Produktions-Override
- Starten der Umgebungen
- Der Weg zu Azure
- Was das Muster über Softwareentwicklung aussagt
- Lokal oder Cloud für KI
- Alle Artikel der Serie
Das Problem mit zwei docker-compose-Dateien
Jeder kennt das Szenario: docker-compose.yml für lokal, docker-compose.prod.yml für die Cloud, und ab einem gewissen Punkt weiß niemand mehr genau, was sich wo unterscheidet.
Services, die lokal laufen, fehlen in der Produktion. Environment Variables, die in der Produktion gesetzt sind, fehlen lokal. Gesundheitschecks, Volumes, Netzwerke, alles beginnt auseinanderzudriften.
Das Docker Compose Override-Pattern löst dieses Problem durch eine klare Hierarchie:
docker-compose.yml # base: always applies
docker-compose.override.yml # local: merged automatically (no -f flag needed)
docker-compose.prod.yml # production: specified explicitly with -fDas Ergebnis: Eine einzige Wahrheitsquelle für die Basis-Konfiguration, umgebungsspezifische Abweichungen in dedizierten Override-Dateien.
Die Basis-Konfiguration
services:
qdrant:
image: qdrant/qdrant:latest
ports:
- '6333:6333'
volumes:
- qdrant_storage:/qdrant/storage
healthcheck:
test: ['CMD', 'curl', '-f', 'http://localhost:6333/healthz']
interval: 10s
timeout: 5s
retries: 5
backend:
build: ./backend
ports:
- '3000:3000'
environment:
- QDRANT_URL=http://qdrant:6333
- PROVIDER=${PROVIDER:-ollama}
- OLLAMA_URL=http://ollama:11434
- VECTOR_SIZE=768
- COLLECTION_NAME=instagram_memory
depends_on:
qdrant:
condition: service_healthy
frontend:
build: ./frontend
ports:
- '5173:80'
depends_on:
- backend
volumes:
qdrant_storage:Diese Datei ist umgebungsagnostisch. Sie definiert die Services, ihre Abhängigkeiten und ihre Ports. Was sie nicht definiert: welcher AI-Provider genutzt wird und ob Ollama dabei ist.
Der ${PROVIDER:-ollama} Syntax ist ein Docker-Compose-Default: Falls die Umgebungsvariable nicht gesetzt ist, wird ollama verwendet. Das ist ein sicherer Default für lokale Entwicklung.
Der lokale Override
Docker Compose lädt docker-compose.override.yml automatisch, sobald docker-compose up ohne weitere Flags aufgerufen wird. Kein -f-Flag nötig.
# automatically loaded for local development
services:
ollama:
image: ollama/ollama:latest
volumes:
- ollama_data:/root/.ollama
# No host port mapping: backend reaches Ollama via internal Docker network.
# Enable only if no local Ollama service is running on port 11434
# and Ollama needs to be reachable from the host:
# ports:
# - "11434:11434"
# GPU support (optional, uncomment if available):
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities: [gpu]
backend:
environment:
- PROVIDER=ollama
- OLLAMA_URL=http://ollama:11434
depends_on:
- ollama
volumes:
ollama_data:Was dieser Override tut:
- Fügt den Ollama-Service hinzu – läuft als Container, kein lokales Install nötig
- Überschreibt
PROVIDER=ollamaim Backend explizit - Erstellt ein persistentes Volume
ollama_data– einmal heruntergeladene Modelle bleiben erhalten - Stellt GPU-Support bereit (auskommentiert, für alle die NVIDIA haben)
- Kein Host-Port-Mapping für Ollama – das Backend erreicht Ollama intern via
http://ollama:11434. Ein Host-Port-Mapping würde mit einem bereits laufenden lokalen Ollama-Dienst kollidieren (address already in use). Das Mapping ist auskommentiert und kann bei Bedarf aktiviert werden.
Das Merging durch Docker Compose ist intelligent: Services aus der Override-Datei werden mit den Basis-Services zusammengeführt. Der backend-Service aus dem Override erweitert den backend-Service aus der Basis, er ersetzt ihn nicht.
Der Produktions-Override
# explicitly loaded for production with -f
services:
backend:
environment:
- PROVIDER=openai
- OPENAI_API_KEY=${OPENAI_API_KEY}
# no OLLAMA_URL needed for OpenAI
# no Ollama service: saves resources and cost in the cloudDieser Override:
- Setzt
PROVIDER=openai– das Backend startet mit dem OpenAI-Provider - Injiziert
OPENAI_API_KEYaus der Shell-Umgebung - Enthält keinen Ollama-Service – in der Cloud zahlt man für Compute, also kein Container der nicht gebraucht wird
Starten der Umgebungen
# local (automatic override): models are downloaded automatically on first start
docker-compose up --build -d
# production (explicit override):
export OPENAI_API_KEY=sk-...
docker-compose -f docker-compose.yml -f docker-compose.prod.yml up -dBeim ersten lokalen Start lädt der Ollama-Container automatisch nomic-embed-text und llama3.2 via ollama/entrypoint.sh. Kein manueller docker exec-Schritt notwendig.
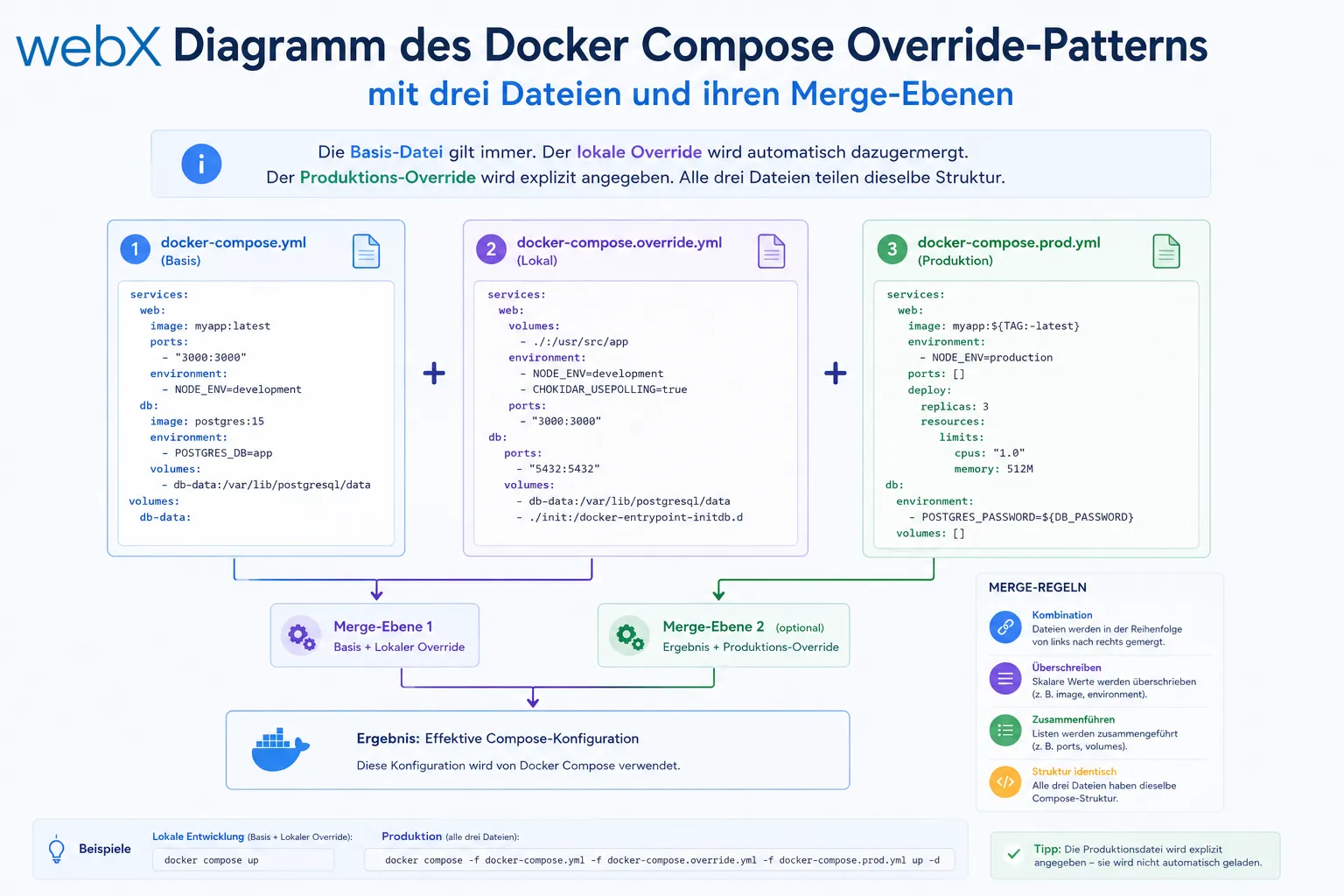 Die Basis-Datei gilt immer. Der lokale Override wird automatisch dazugemergt. Der Produktions-Override wird explizit angegeben. Alle drei Dateien teilen dieselbe Struktur.
Die Basis-Datei gilt immer. Der lokale Override wird automatisch dazugemergt. Der Produktions-Override wird explizit angegeben. Alle drei Dateien teilen dieselbe Struktur.
Der Weg zu Azure
Wenn dieses System auf Azure deployed wird, bieten sich mehrere Optionen an:
Azure Container Apps
Azure Container Apps unterstützt Docker Compose nativ über das containerapp compose CLI. Das bedeutet: Die bestehenden Compose-Dateien können direkt verwendet werden.
az containerapp compose create \
--resource-group myRG \
--environment myEnv \
--compose-file-path docker-compose.yml \
--compose-file-path docker-compose.prod.ymlQdrant wird als Container-App deployed, Backend als Container-App, Frontend als statische Web-App oder Container-App. Keine Kubernetes-Komplexität, automatisches Scaling, Managed Certificates.
Azure Container Instances
Für kleinere Deployments ohne automatisches Scaling eignen sich Azure Container Instances mit einer YAML-Deployment-Definition, die aus den Compose-Dateien abgeleitet wird.
AKS
Wenn Kubernetes benötigt wird (z.B. für Enterprise-Skalierung oder bestehende AKS-Cluster), lassen sich die Compose-Dateien mit kompose convert in Kubernetes-Manifeste überführen. Die Provider-Abstraktion bleibt identisch, nur die Deployment-Plattform ändert sich.
Was das Muster über Softwareentwicklung aussagt
Das Override-Pattern ist keine Docker-spezifische Technik. Es ist eine Anwendung desselben Prinzips, das ich überall in guten Systemen sehe:
Separation of Concerns durch Layering.
Eine Basis, die immer gilt. Schichten darüber, die umgebungsspezifisches Verhalten hinzufügen, ohne die Basis zu ändern. Jede Schicht ist klein, lesbar, verständlich.
In der Praxis bedeutet das:
- Ein Entwickler, der neu ins Projekt kommt, führt
docker-compose upaus. Es funktioniert. - Ein DevOps-Engineer, der die Produktion deployed, verwendet dieselbe Basis-Datei plus ein Override. Kein Hidden State, keine Überraschungen.
- Wenn sich die Produktion ändert (z.B. Wechsel von OpenAI zu Azure OpenAI), ändert man das Override. Die Basis bleibt unberührt.
Lokal oder Cloud für KI
Das war eine der ersten Fragen, die ich mir gestellt habe: Soll ich Ollama lokal oder in der Cloud hosten?
Die Antwort hängt vom Anwendungsfall ab:
| Faktor | Ollama lokal/Docker | OpenAI Cloud |
|---|---|---|
| Kosten bei niedrigem Volumen | Kostenlos | Minimal (~$0.02/1000 Anfragen) |
| Kosten bei hohem Volumen | Fix (Hardware) | Skaliert mit Nutzung |
| Datenschutz | Alles lokal | Daten gehen zu OpenAI |
| Verfügbarkeit | Eigene Infra | 99.9% SLA |
| Wartungsaufwand | Modell-Updates nötig | Managed |
| Performance (Cold Start) | Langsam auf CPU | Schnell |
Für Proof-of-Concepts und Entwicklung: Ollama. Für produktive Systeme mit vielen Nutzern: OpenAI oder Azure OpenAI. Für Systeme mit strengen Datenschutzanforderungen: Ollama auf eigenem Server oder Azure OpenAI in einer private Deployment-Konfiguration.
Das Override-Pattern macht diesen Wechsel zu einem operativen, nicht architektonischen Entscheid. Das ist der Punkt.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure (dieser Artikel)
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
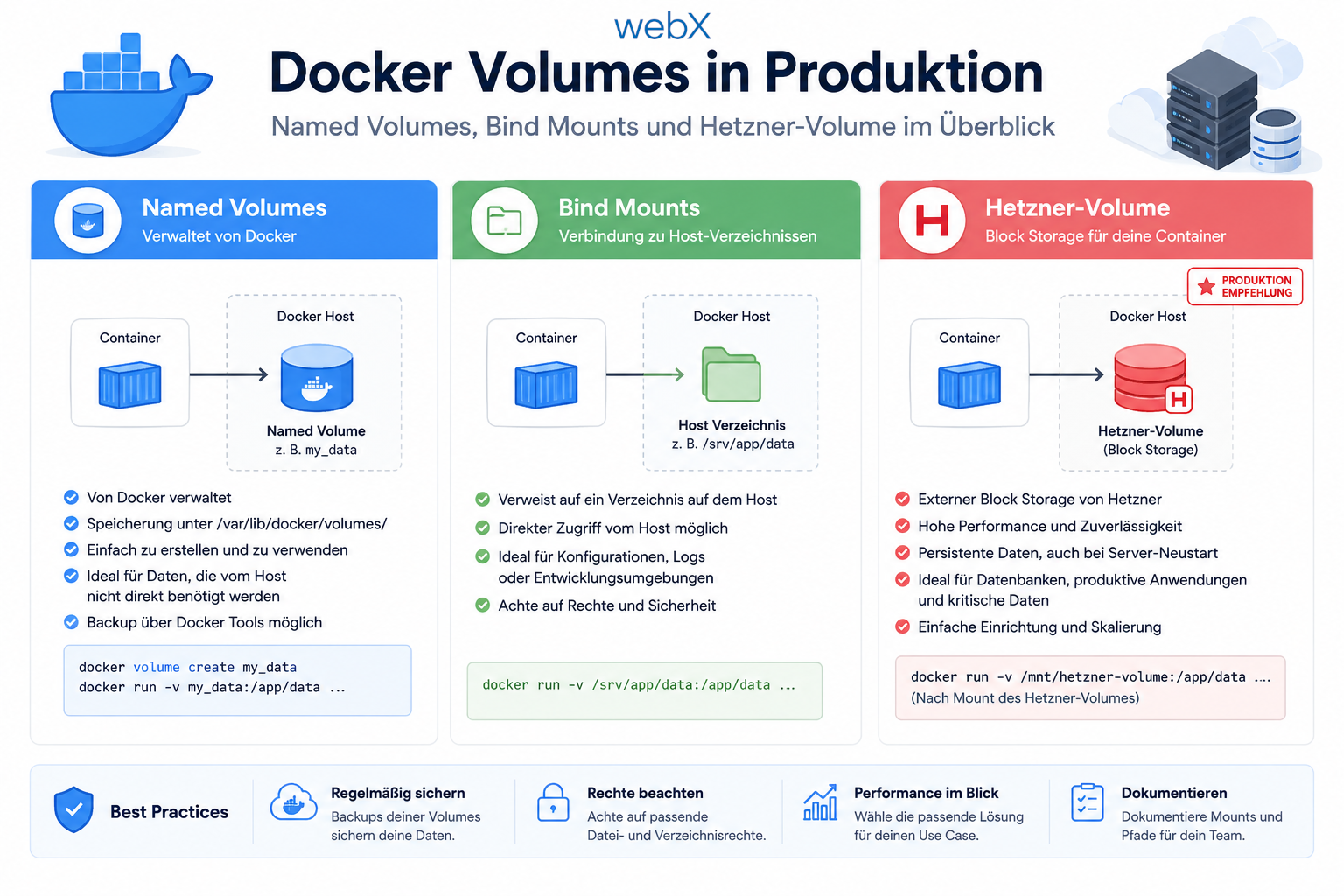
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
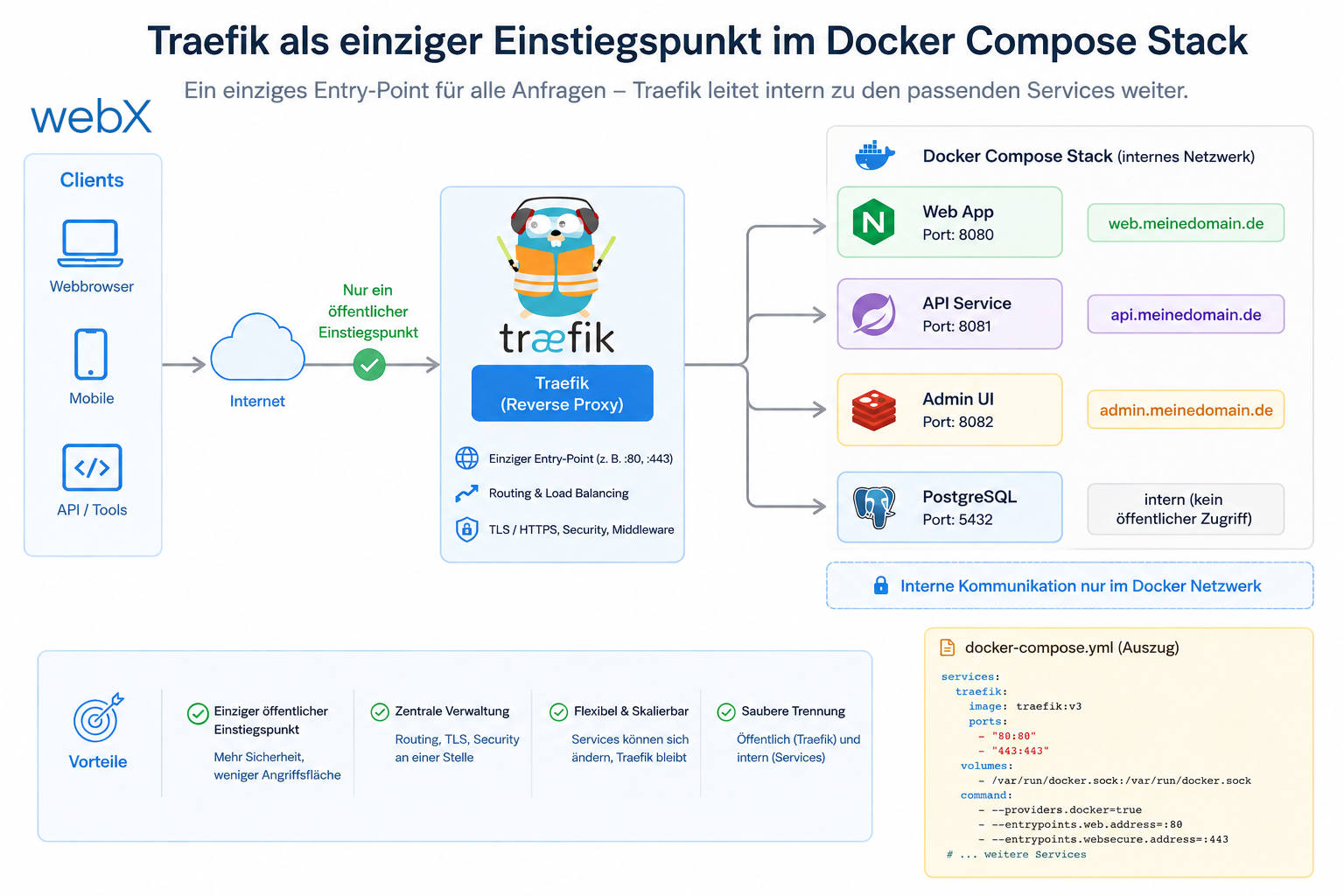
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
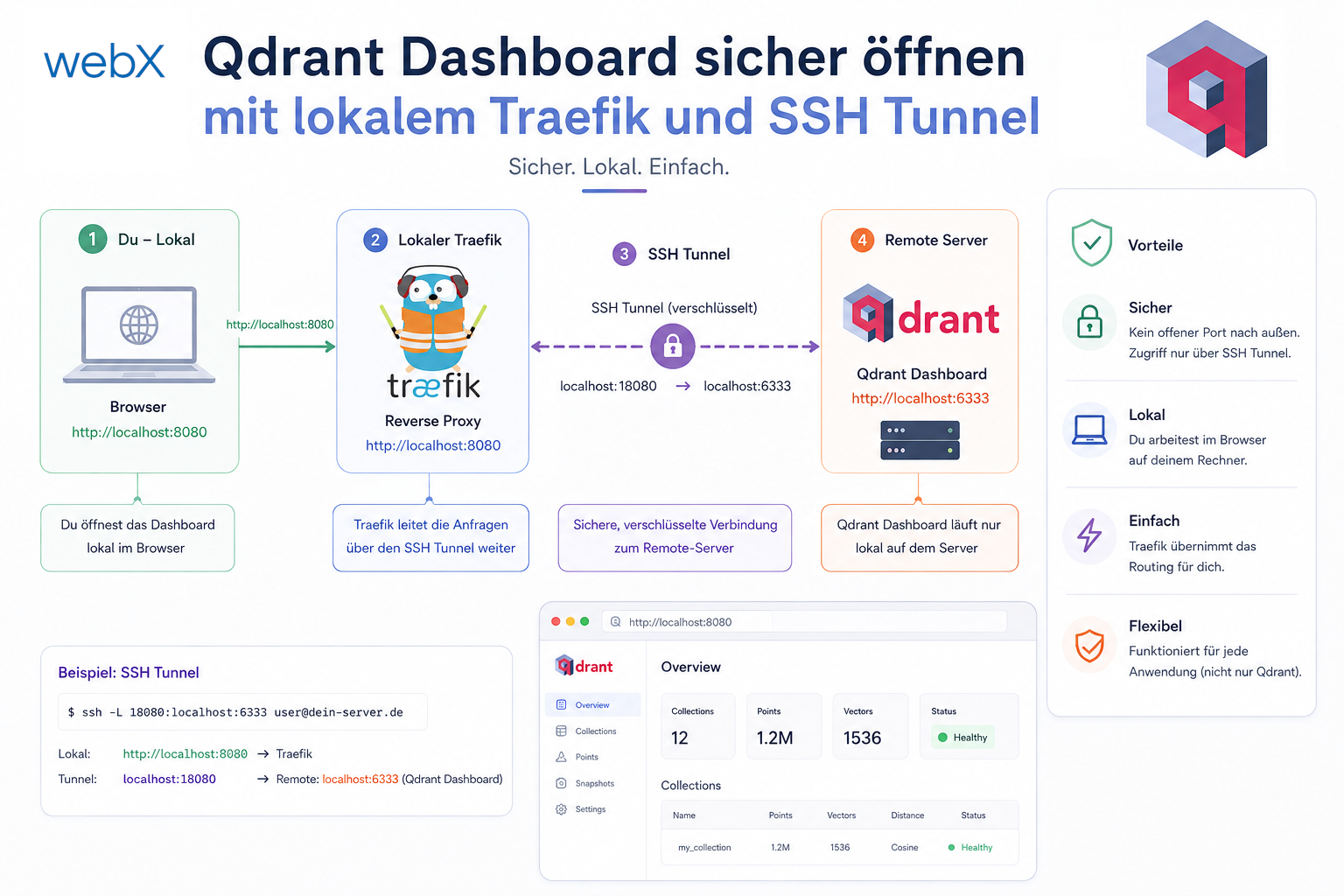
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du planst eine Cloud-Deployment-Strategie für ein KI-System und willst Entwicklung und Produktion sauber trennen? Lass uns das gemeinsam einschätzen.