· David Göschel · Architektur · 7 minuten Lesezeit
AI Provider Abstraktion für ein flexibles RAG-System mit Ollama und OpenAI
Ich hätte Ollama direkt ins Backend einbauen können. Ich hätte OpenAI direkt einbauen können. Ich habe stattdessen eine Abstraktionsschicht gebaut, die beide erlaubt, und dabei verstanden, warum das keine Überentwicklung ist, sondern die einzig strategisch richtige Entscheidung.
Inhalt
- Lokal oder Cloud?
- Ein Provider-Interface
- OllamaProvider
- OpenAIProvider
- Backward Compatibility
- Wechsel in der Praxis
- Was das über Software-Architektur aussagt
- Was das für Kundenprojekte bedeutet
- Alle Artikel der Serie
Lokal oder Cloud?
Beim Aufbau eines KI-Systems taucht irgendwann diese Frage auf: Ollama oder OpenAI?
Ollama ist kostenlos, privat, läuft lokal. Keine API-Kosten, keine Datenschutzbedenken, keine externe Abhängigkeit. Dafür: Hardwareanforderungen, keine automatische Skalierbarkeit, manuelle Modellverwaltung.
OpenAI ist sofort skalierbar, hochperformant, wartungsfrei. Dafür: Kosten pro Token, Datenschutzfragen, externe Abhängigkeit.
Die meisten Entwickler treffen diese Entscheidung einmal und leben dann mit den Konsequenzen. Ich habe sie anders gestellt: Warum muss ich mich überhaupt entscheiden?
Ein Provider-Interface
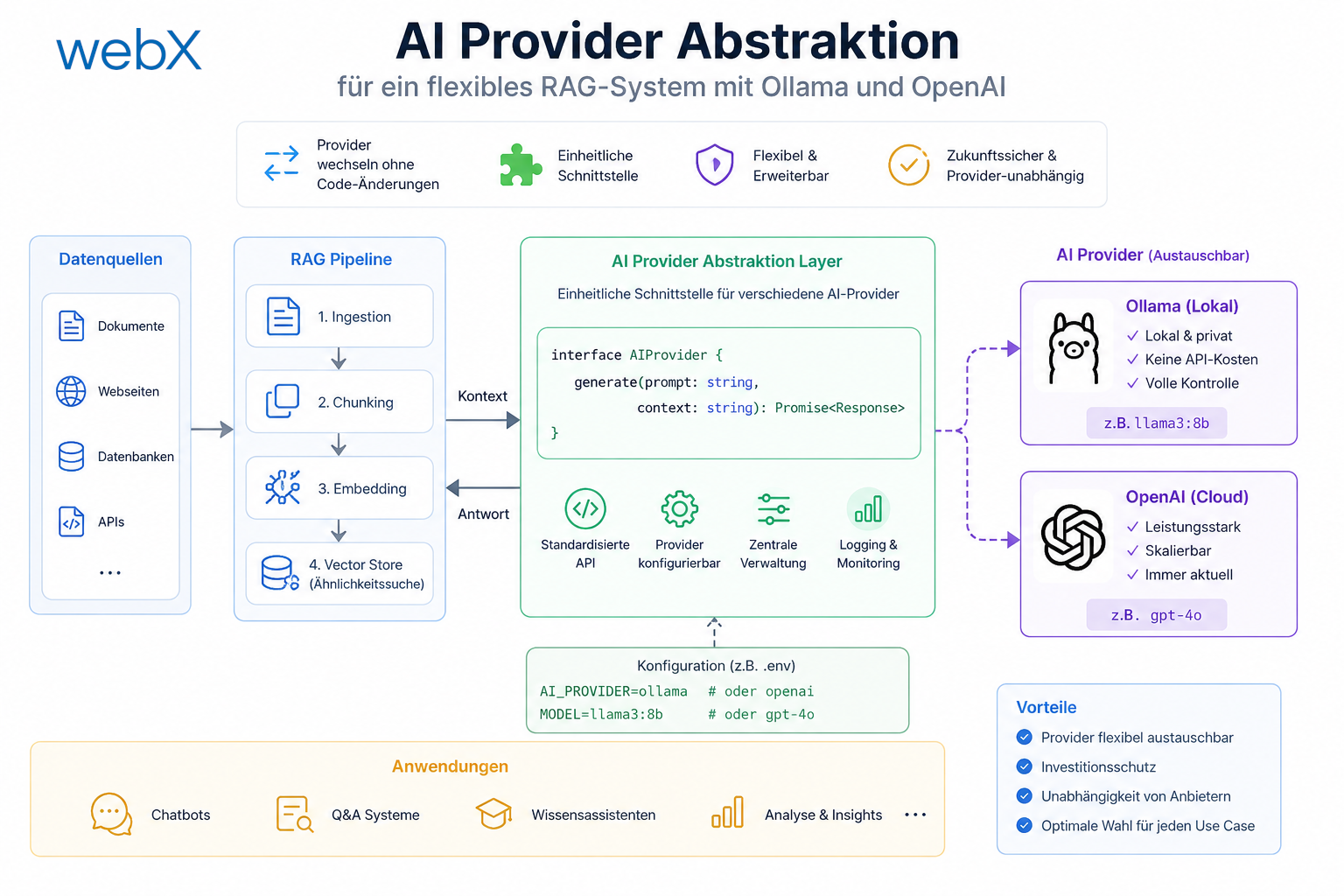
Das Prinzip ist simpel: Ich definiere, was ein AI Provider können muss, und überlasse der Umgebungsvariable die Entscheidung, welche Implementierung geladen wird.
// src/services/ai-provider.ts
interface AIProvider {
generateEmbedding(text: string): Promise<number[]>;
generateAnswer(query: string, context: string): Promise<string>;
checkHealth(): Promise<void>; // throws if provider is unreachable
}Das ist bewusst minimal. Kein generisches API, kein über-abstrahiertes Framework. Drei Methoden, die genau das tun, was das Backend braucht.
Die Factory-Funktion:
let providerInstance: AIProvider | null = null;
export function getProvider(): AIProvider {
if (providerInstance) return providerInstance;
const providerName = process.env.PROVIDER ?? 'ollama';
switch (providerName) {
case 'ollama':
providerInstance = new OllamaProvider();
break;
case 'openai':
providerInstance = new OpenAIProvider();
break;
default:
throw new Error(`Unknown provider: ${providerName}`);
}
console.log(`[AI] Provider initialized: ${providerName}`);
return providerInstance;
}Singleton-Pattern: getProvider() erstellt die Instanz nur einmal. Jeder weitere Aufruf gibt dieselbe Instanz zurück. Das ist wichtig für Ressourcenmanagement, weil keine wiederholten Client-Initialisierungen pro Request entstehen.
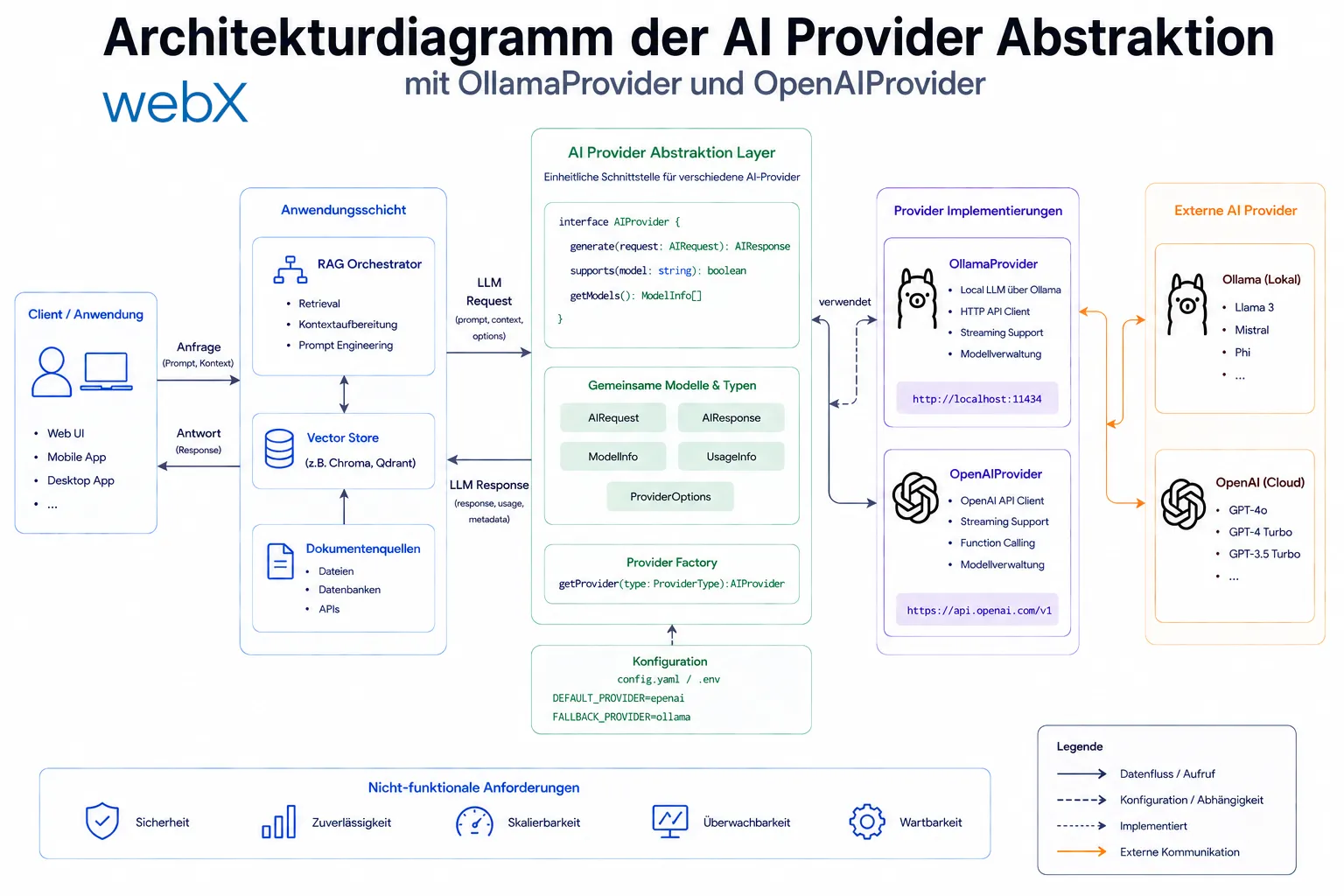 Abbildung: Das Interface trennt die Nutzungsseite (Routes) vollständig von der Implementierungsseite. Welcher Provider aktiv ist, bestimmt ausschließlich eine Umgebungsvariable.
Abbildung: Das Interface trennt die Nutzungsseite (Routes) vollständig von der Implementierungsseite. Welcher Provider aktiv ist, bestimmt ausschließlich eine Umgebungsvariable.
OllamaProvider
// src/services/providers/ollama-provider.ts
export class OllamaProvider implements AIProvider {
private readonly ollamaUrl: string;
private readonly embeddingModel: string;
private readonly generationModel: string;
constructor() {
this.ollamaUrl = process.env.OLLAMA_URL ?? 'http://ollama:11434';
this.embeddingModel = process.env.EMBEDDING_MODEL ?? 'nomic-embed-text';
this.generationModel = process.env.GENERATION_MODEL ?? 'llama3.2';
}
async generateEmbedding(text: string): Promise<number[]> {
const response = await fetch(`${this.ollamaUrl}/api/embeddings`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ model: this.embeddingModel, prompt: text }),
});
const data = await response.json();
return data.embedding;
}
async generateAnswer(query: string, context: string): Promise<string> {
const prompt = `You are an OSINT analysis assistant. Use the following context to answer the analyst's question accurately.\n\nContext:\n${context}\n\nQuestion: ${query}`;
const response = await fetch(`${this.ollamaUrl}/api/generate`, {
method: 'POST',
body: JSON.stringify({
model: this.generationModel,
prompt,
stream: false,
}),
});
const data = await response.json();
return data.response;
}
async checkHealth(): Promise<void> {
const response = await fetch(`${this.ollamaUrl}/api/tags`);
if (!response.ok) throw new Error('Ollama is not reachable');
}
}Direkte HTTP-Aufrufe gegen die Ollama-REST-API. Kein SDK, kein Overhead. Ollamals API ist stabil und gut dokumentiert.
OpenAIProvider
// src/services/providers/openai-provider.ts
import OpenAI from 'openai';
export class OpenAIProvider implements AIProvider {
private readonly client: OpenAI;
private readonly embeddingModel: string;
private readonly generationModel: string;
constructor() {
const apiKey = process.env.OPENAI_API_KEY;
if (!apiKey) {
throw new Error('OPENAI_API_KEY is required when using the OpenAI provider');
}
this.client = new OpenAI({ apiKey });
this.embeddingModel = process.env.EMBEDDING_MODEL ?? 'text-embedding-3-small';
this.generationModel = process.env.GENERATION_MODEL ?? 'gpt-4o-mini';
}
async generateEmbedding(text: string): Promise<number[]> {
const response = await this.client.embeddings.create({
model: this.embeddingModel,
input: text,
dimensions: 768, // explicitly reduced to 768 for Qdrant compatibility
});
return response.data[0].embedding;
}
async generateAnswer(query: string, context: string): Promise<string> {
const completion = await this.client.chat.completions.create({
model: this.generationModel,
messages: [
{ role: 'system', content: 'You are an OSINT analysis assistant for stored social media posts.' },
{ role: 'user', content: `Context:\n${context}\n\nQuestion: ${query}` },
],
});
return completion.choices[0]?.message?.content ?? '';
}
async checkHealth(): Promise<void> {
// minimal API call for health verification
await this.client.models.list();
}
}Zwei Details sind hier entscheidend:
1. Fail-Fast im Konstruktor:
if (!apiKey) {
throw new Error('OPENAI_API_KEY is required when using the OpenAI provider');
}Wenn PROVIDER=openai gesetzt ist, aber der API-Key fehlt, startet der Server gar nicht. Keine stillen Fehler zur Laufzeit. Das ist Fail-Fast: Probleme so früh wie möglich sichtbar machen.
2. dimensions: 768: OpenAIs text-embedding-3-small produziert standardmäßig 1536-dimensionale Vektoren. Mit dem dimensions-Parameter lässt sich das reduzieren, ohne signifikanten Qualitätsverlust, aber mit dem entscheidenden Vorteil, dass die Qdrant-Collection kompatibel bleibt. Das bedeutet: Ich kann von Ollama auf OpenAI wechseln (oder zurück), ohne die Daten in Qdrant zu migrieren. Die Vektordimensionen stimmen immer überein.
Backward Compatibility
Das Backend hatte vor der Abstraktion direkten Zugriff auf Ollama-Funktionen via services/ollama.ts. Anstatt alle Route-Handler umzuschreiben, habe ich ollama.ts zu einem Re-Export gemacht:
// src/services/ollama.ts (after refactoring)
export { generateEmbedding, generateAnswer, checkProviderHealth } from './ai-provider';Alle Route-Handler importieren weiterhin aus services/ollama.ts. Sie merken nichts von der Abstraktion darunter.
Wechsel in der Praxis
Lokal (Standard):
# docker-compose.override.yml is loaded automatically
docker-compose up -d
# PROVIDER=ollama (default), Ollama runs as a containerProduktion (OpenAI):
export OPENAI_API_KEY=sk-...
docker-compose -f docker-compose.yml -f docker-compose.prod.yml up -d
# PROVIDER=openai, no Ollama containerDas ist alles. Kein Code-Wechsel. Kein Rebuild. Nur eine andere Compose-Datei.
Was das über Software-Architektur aussagt
Diese Abstraktion ist kein cleverer Trick. Sie ist eine direkte Anwendung von zwei Grundprinzipien:
Dependency Inversion Principle: High-Level-Module (die Routes) sollten nicht von Low-Level-Modulen (Ollama, OpenAI) abhängen. Beide sollten von Abstraktionen abhängen.
Open/Closed Principle: Das System ist offen für Erweiterungen (neuer Provider: eine neue Klasse, eine neue case-Zeile) und geschlossen für Modifikation (bestehende Routes, Tests, Logik werden nicht angefasst).
Was das für Kundenprojekte bedeutet
Wenn ich ein Power Pages Portal mit KI-Suche erweitere, ist die Provider-Frage immer präsent:
- Entwicklungsphase: Ollama lokal, keine Kosten, kein Datenschutz-Problem mit echten Kundendaten
- Staging: Ollama in Docker, identisch zur Produktion, aber günstig
- Produktion: OpenAI oder Azure OpenAI, skalierbar, SLA-gesichert
Dieser Wechsel kostet bei richtiger Architektur eine Umgebungsvariable. Das ist das Ziel.
Wenn ein Kunde in zwei Jahren auf Azure OpenAI wechseln will, weil er Data Residency in Europa braucht, dann ist das ein halber Tag Arbeit, kein Rewrite.
Das ist der Unterschied zwischen einem Feature bauen und eine Architektur bauen.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
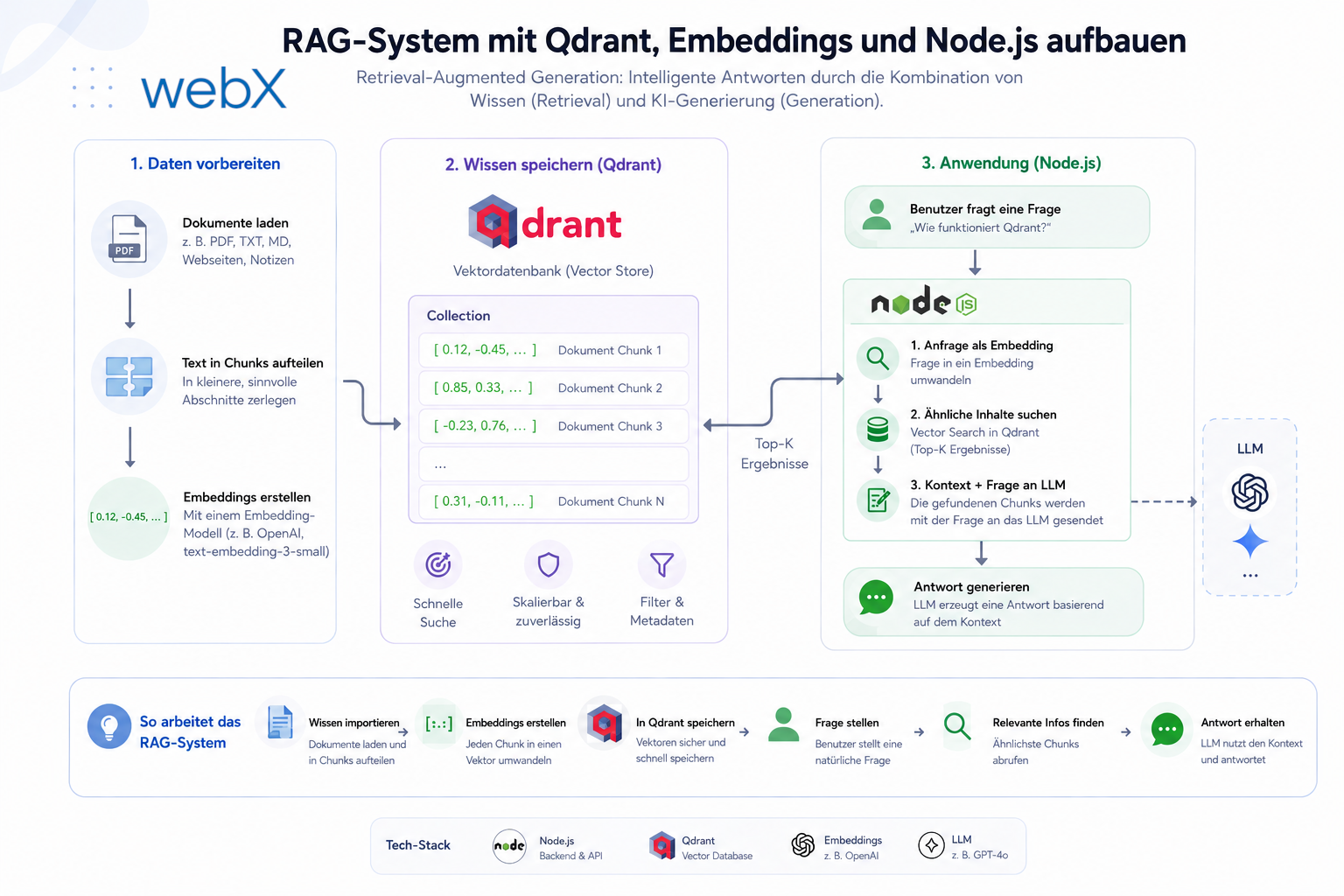
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: (dieser Artikel)
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
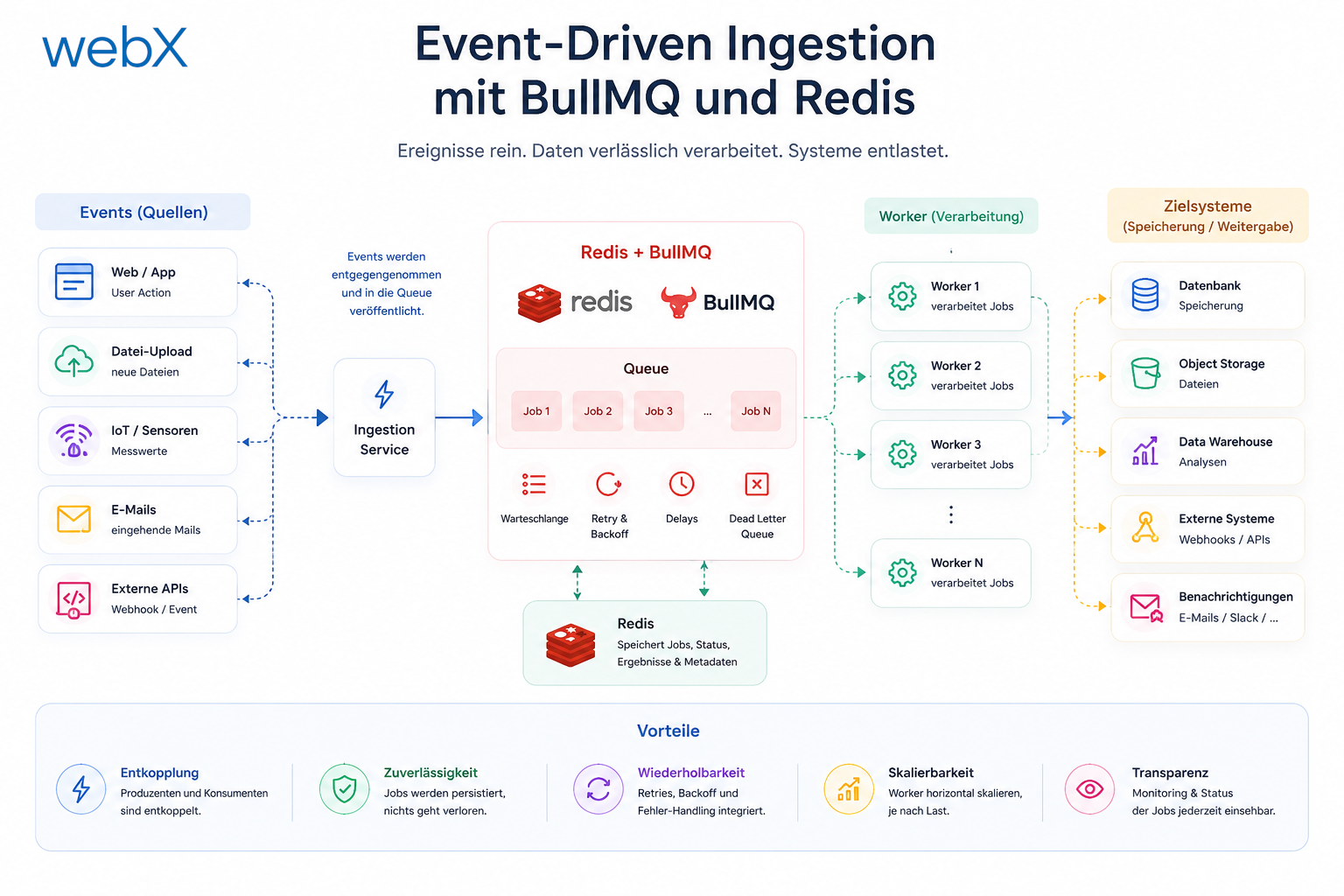
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
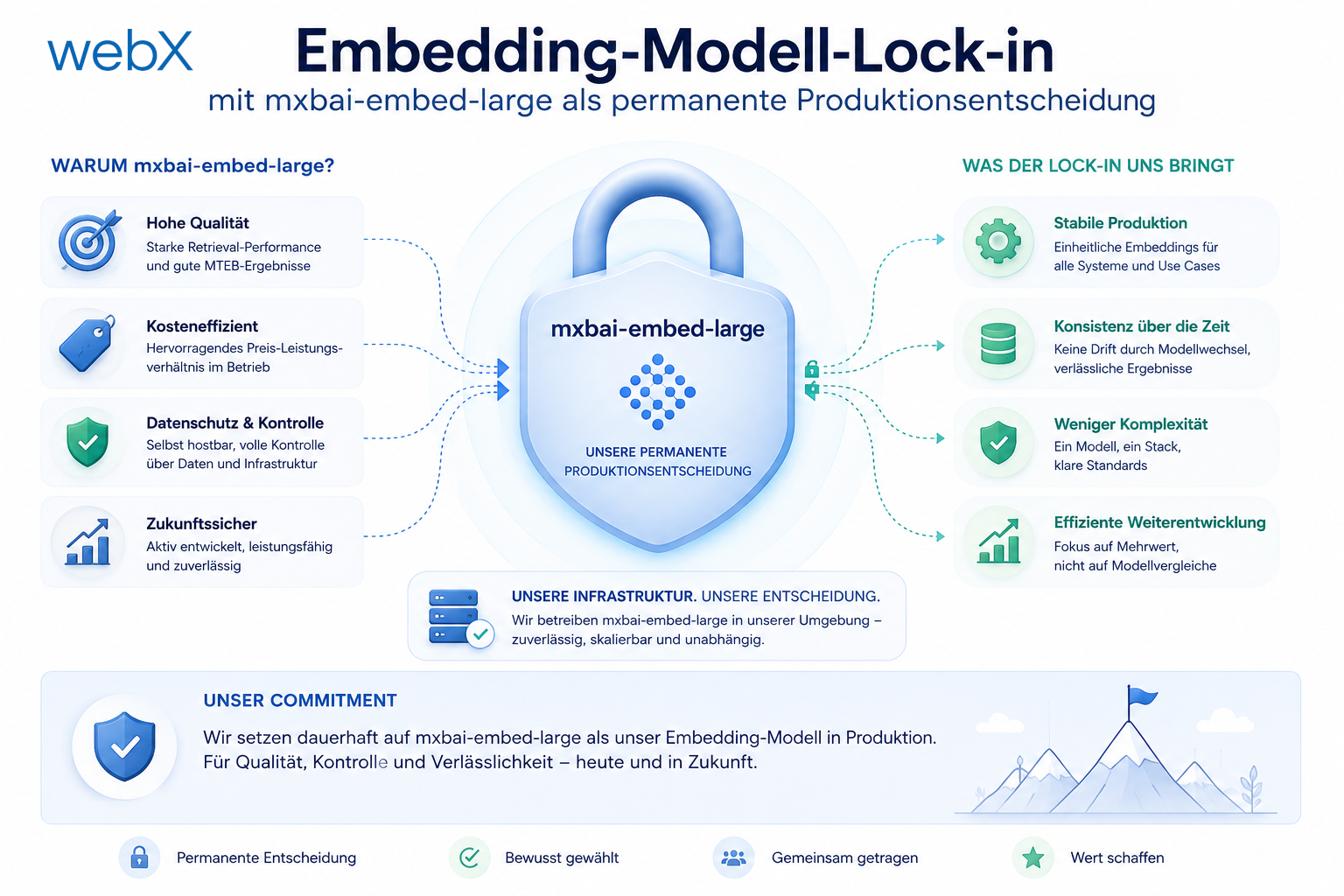
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
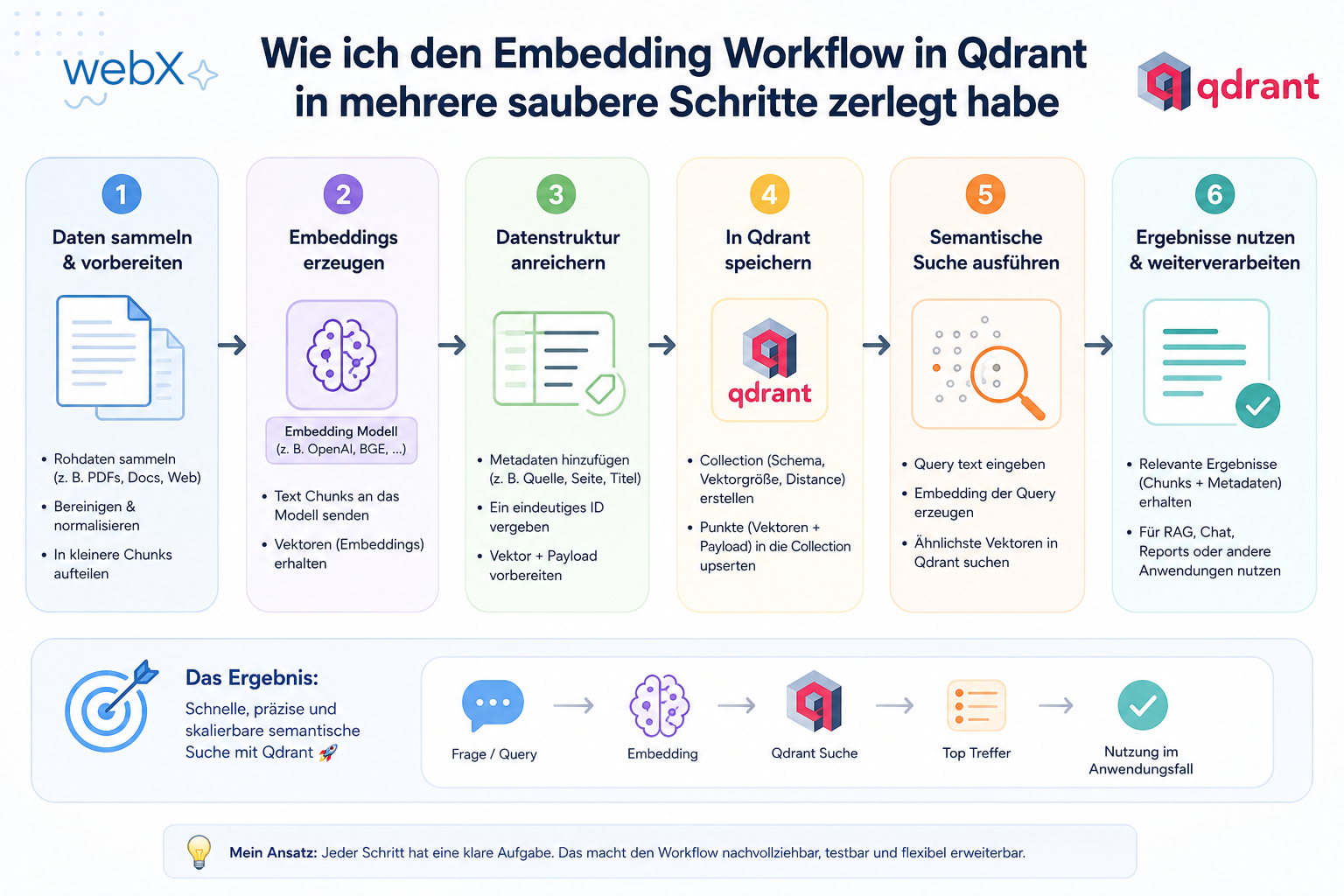
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du planst ein Power Pages Portal mit KI-gestützter Suche und überlegst, welcher Provider-Ansatz für dein Projekt passt? Lass uns das gemeinsam einschätzen.