· David Göschel · Architektur · 8 minuten Lesezeit
Event-Driven Ingestion mit BullMQ und Redis
POST /ingest blockierte die Extension, bis Embedding und Qdrant-Upsert fertig waren. Mit BullMQ und Redis wird der Ingest asynchron: 202 sofort, Verarbeitung im Hintergrund, Statusabfrage über GET /captures/:id/status.
Inhalt
- Das Problem mit synchronem Ingest
- Was ich stattdessen wollte
- Warum BullMQ und nicht einfach setImmediate
- Redis in den Docker-Compose-Stack einbauen
- Die Queue-Konfiguration im Backend
- Der Ingest-Worker
- Die neue Ingest-Route
- Der Statusabfrage-Endpoint
- Die Extension-Seite
- Graceful Shutdown
- Was das konkret ändert
- Alle Artikel der Serie
Das Problem mit synchronem Ingest
Ich hatte ein funktionierendes System. Die Chrome Extension drückt Ctrl+Q, der Post wird erkannt, Screenshot wird zugeschnitten, und dann kommt POST /ingest. Das Backend macht drei Dinge nacheinander: Bild nach Azure Blob Storage hochladen, Embedding über Ollama oder OpenAI generieren, Vektor in Qdrant speichern.
Funktioniert. Aber mit einem Problem, das ich lange ignoriert hatte.
Das Embedding bei OpenAI dauert zwischen 300 ms und 1.500 ms, je nach Auslastung. Ollama lokal ist noch langsamer. Solange das Backend diese Kette durchläuft, hält es die HTTP-Verbindung zur Extension offen. Die Extension hängt. Der Nutzer wartet. Und wenn das Backend neu gestartet wird, während gerade ein Capture in der Pipeline steckt, geht dieser Capture verloren.
Das ist kein Edge Case. Das ist schlechtes Design.
Was ich stattdessen wollte
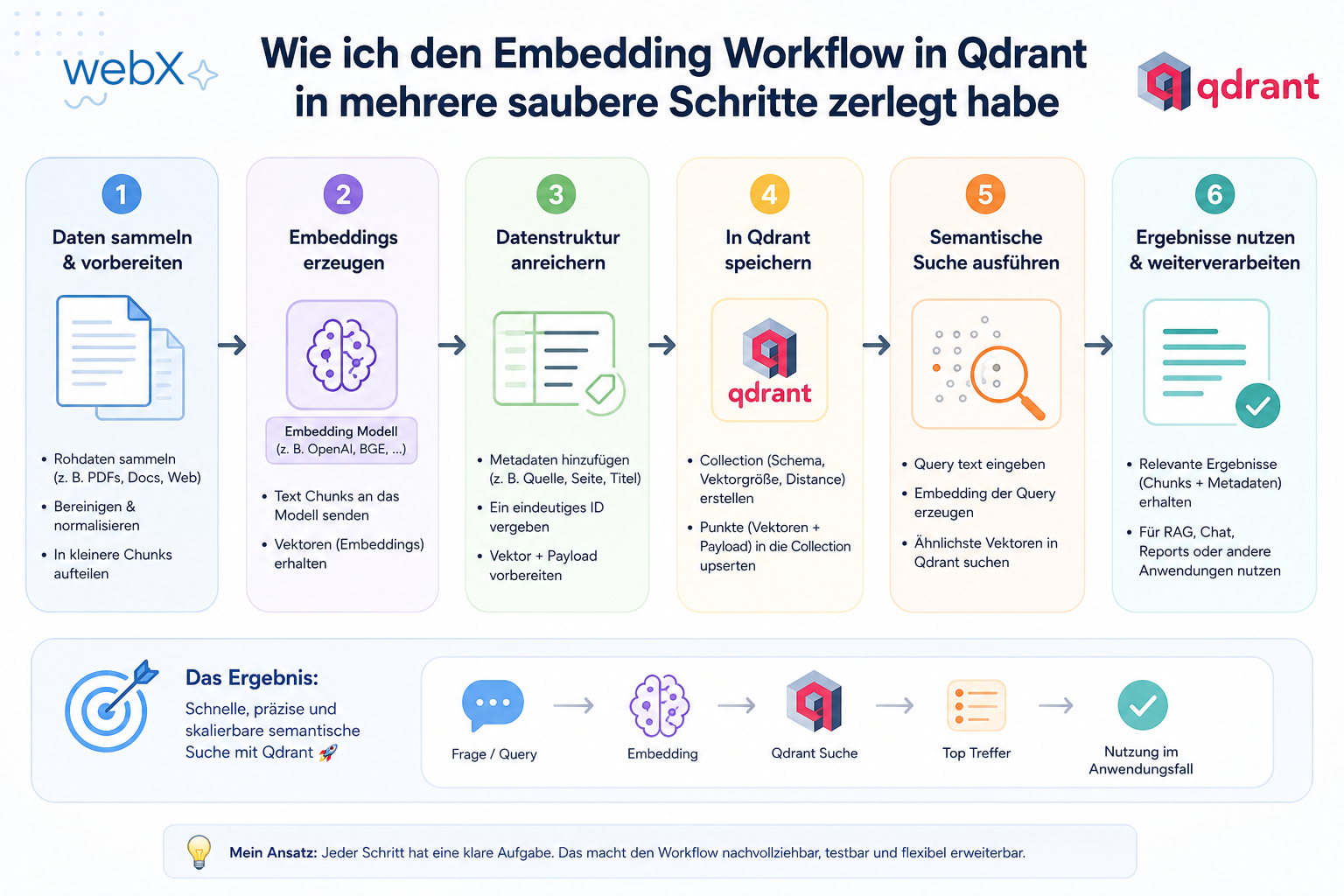
Die Extension soll feuern und vergessen. POST /ingest gibt 202 Accepted zurück, sobald das Bild hochgeladen ist. Die Antwort enthält eine captureId. Den Rest erledigt ein Worker im Hintergrund: Embedding und Qdrant-Upsert.
Extension → POST /ingest
← 202 { captureId } ← sofort
Backend-Worker (async):
→ generateEmbedding(text)
→ storePoint(vector, payload, captureId)
→ job.state = "completed"
Extension → GET /captures/:captureId/status
← { status: "completed" }Genau das ist das Event-Driven-Prinzip: Produzent und Konsument sind entkoppelt. Der Produzent (API) weiß nicht, wie lange die Verarbeitung dauert. Er gibt Job in eine Queue, fertig.
Warum BullMQ und nicht einfach setImmediate
Die einfachste Variante wäre: setImmediate(() => processInBackground(...)). HTTP antwortet sofort, Worker läuft in demselben Node.js-Prozess, keine neue Abhängigkeit.
Das Problem: Bei einem Prozess-Crash gehen alle Jobs verloren, die noch nicht abgearbeitet wurden. Es gibt keine Retry-Logik. Kein Monitoring. Keine Möglichkeit, von außen zu sehen, was gerade verarbeitet wird.
BullMQ löst das mit Redis als persistenter Queue. Ein Job bleibt in Redis, bis der Worker ihn als completed oder failed markiert. Server-Restart kostet keinen einzigen Job.
Kafka wäre overkill für diesen Use Case. Kafka ist sinnvoll ab einigen Millionen Events pro Tag, wenn mehrere unabhängige Consumer-Groups denselben Stream lesen müssen. BullMQ mit Redis skaliert auf 100.000 Jobs täglich ohne jede Konfigurationsänderung. Mehr Worker-Container starten reicht aus.
Redis in den Docker-Compose-Stack einbauen
In docker-compose.yml reicht ein einzelner Service:
# Added in Phase 2: Redis as BullMQ queue broker
redis:
image: redis:7-alpine
container_name: redis_local
ports:
- "6379:6379"
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 3s
retries: 5Der Backend-Service bekommt eine neue Umgebungsvariable:
backend:
environment:
- REDIS_URL=redis://redis:6379
depends_on:
- redisIm docker-compose.override.yml wird der Backend-Service noch um redis in der depends_on-Liste erweitert, damit der lokale Stack in der richtigen Reihenfolge hochfährt.
Die Queue-Konfiguration im Backend
In src/services/queue.ts sitzt der BullMQ-Queue-Singleton:
// src/services/queue.ts
import { Queue } from "bullmq";
import type { IngestJobData } from "../types";
function parseRedisUrl(url: string): { host: string; port: number } {
const parsed = new URL(url);
return { host: parsed.hostname, port: parseInt(parsed.port || "6379", 10) };
}
export const connection = parseRedisUrl(process.env.REDIS_URL || "redis://localhost:6379");
export const ingestionQueue = new Queue<IngestJobData>("ingestion", {
connection,
defaultJobOptions: {
attempts: 3,
backoff: { type: "exponential", delay: 2000 },
removeOnComplete: { count: 500 },
removeOnFail: { count: 100 },
},
});attempts: 3 mit exponentiellem Backoff (2 s, 4 s, 8 s) deckt temporäre Ausfälle von Ollama oder OpenAI ab. Die meisten Embedding-Fehler sind transient.
removeOnComplete und removeOnFail verhindern, dass Redis mit abgelaufenen Job-Einträgen volläuft. Ich behalte 500 erfolgreiche und 100 fehlgeschlagene Jobs für die Statusabfrage.
Der Ingest-Worker
// src/workers/ingest-worker.ts
import { Worker, type Job } from "bullmq";
import type { IngestJobData } from "../types";
import { generateEmbedding } from "../services/ai-provider";
import { storePoint } from "../services/qdrant";
import { connection, INGESTION_QUEUE_NAME } from "../services/queue";
async function processIngestJob(job: Job<IngestJobData>): Promise<void> {
const { captureId, qdrantPayload, embeddingText } = job.data;
const vector = await generateEmbedding(embeddingText);
await storePoint(vector, qdrantPayload, captureId);
}
export function createIngestWorker() {
const worker = new Worker<IngestJobData>(INGESTION_QUEUE_NAME, processIngestJob, {
connection,
concurrency: 3,
});
worker.on("failed", (job, err) => {
if (job && job.attemptsMade >= (job.opts?.attempts ?? 3)) {
console.error(`[IngestWorker] DEAD LETTER — captureId ${job.data.captureId}:`, err.message);
}
});
return worker;
}concurrency: 3 bedeutet: der Worker verarbeitet bis zu drei Jobs gleichzeitig. Sinnvoll, wenn mehrere Captures in kurzer Zeit eintreffen. Für OpenAI-Embeddings ist das unproblematisch. Für Ollama lokal kann concurrency: 1 besser sein, um das Modell nicht zu überlasten.
Die storePoint-Funktion in services/qdrant.ts bekommt eine optionale ID:
export async function storePoint(
vector: number[],
payload: QdrantPayload,
id?: string
): Promise<string> {
const pointId = id ?? crypto.randomUUID();
// ...
}Das ist der entscheidende Punkt: Die captureId, die die Extension in 202 { captureId } erhält, ist dieselbe UUID, die später als Qdrant-Dokumenten-ID gespeichert wird. Kein separates ID-Mapping nötig.
Die neue Ingest-Route
// src/routes/ingest.ts (vereinfacht)
router.post("/", async (req, res) => {
const payload = req.body as PlatformAnalysisPayload;
if (!payload?.platform || !payload?.image?.base64) {
res.status(400).json({ error: "Invalid payload" });
return;
}
if (req.auth?.userId) payload.capturedBy.userId = req.auth.userId;
const captureId = crypto.randomUUID();
const embeddingText = buildEmbeddingText(payload);
// Upload image synchronously (fast) — then immediately return
const blobName = await uploadImage(payload.image.base64, payload.image.mimeType);
const qdrantPayload = { ...payload, image: { blobName, ... }, embeddingText };
// Enqueue with captureId as BullMQ job ID
await ingestionQueue.add("ingest", { captureId, qdrantPayload, embeddingText }, { jobId: captureId });
res.status(202).json({ captureId });
});Das Bild wird noch synchron hochgeladen, typischerweise unter 200 ms. Das ist kein Blocking-Problem. Der teure Teil (Embedding) ist vollständig ausgelagert.
Der Statusabfrage-Endpoint
// src/routes/captures.ts
router.get("/:captureId/status", async (req, res) => {
const job = await statusQueue.getJob(req.params.captureId);
if (!job) {
res.json({ captureId: req.params.captureId, status: "unknown" });
return;
}
const state = await job.getState();
res.json({ captureId: req.params.captureId, status: state, ...(state === "failed" ? { failedReason: job.failedReason } : {}) });
});Mögliche Status: waiting, active, completed, failed, delayed, unknown.
Die Extension-Seite
In background/main.ts wird das 202-Response jetzt ausgewertet:
if (response.status === 202) {
const { captureId } = await response.json() as { captureId: string };
await appendAsyncCapture(captureId, payload);
}appendAsyncCapture speichert { captureId, channel, platform, capturedAt, status: "waiting" } in chrome.storage.local.asyncCaptures.
Wenn das Popup geöffnet wird, lädt es diese Einträge und fragt für jeden, der noch nicht completed ist, den Backend-Status ab:
const updatedAsync = await refreshAsyncStatuses(asyncCaptures);
await chrome.storage.local.set({ asyncCaptures: trimmed });
renderAsyncCaptures(trimmed);Das Popup zeigt ein neues “Verarbeitung”-Panel mit farbkodierten Status: gelb für warteschlange/verzögert, blau für verarbeitung, rot für fehlgeschlagen.
Graceful Shutdown
In src/index.ts gibt es jetzt einen ordentlichen Shutdown-Handler:
const worker = createIngestWorker();
const shutdown = async () => {
console.log("Shutting down worker...");
await worker.close(); // Wartet, bis der laufende Job abgeschlossen ist
process.exit(0);
};
process.on("SIGTERM", shutdown);
process.on("SIGINT", shutdown);worker.close() lässt den aktuell laufenden Job zu Ende verarbeiten, bevor der Prozess beendet wird. Kein Datenverlust bei docker compose down.
Was das konkret ändert
Vor Phase 2: POST /ingest hält die Extension für 300 ms bis 3 s fest. Ein Backend-Restart während des Embedings verliert den Job.
Nach Phase 2: POST /ingest antwortet in unter 300 ms (Image-Upload + Queue-Enqueue). Ein Backend-Restart verliert keinen einzigen Job. Redis hält die Queue. Der Worker nimmt den Job nach dem Neustart wieder auf.
Für die nächste Phase (Multi-Tenancy, Quota-Enforcement) ist die Architektur bereits vorbereitet: Workers können horizontal skaliert werden, indem man einfach weitere Backend-Container startet. Keine Code-Änderungen nötig.
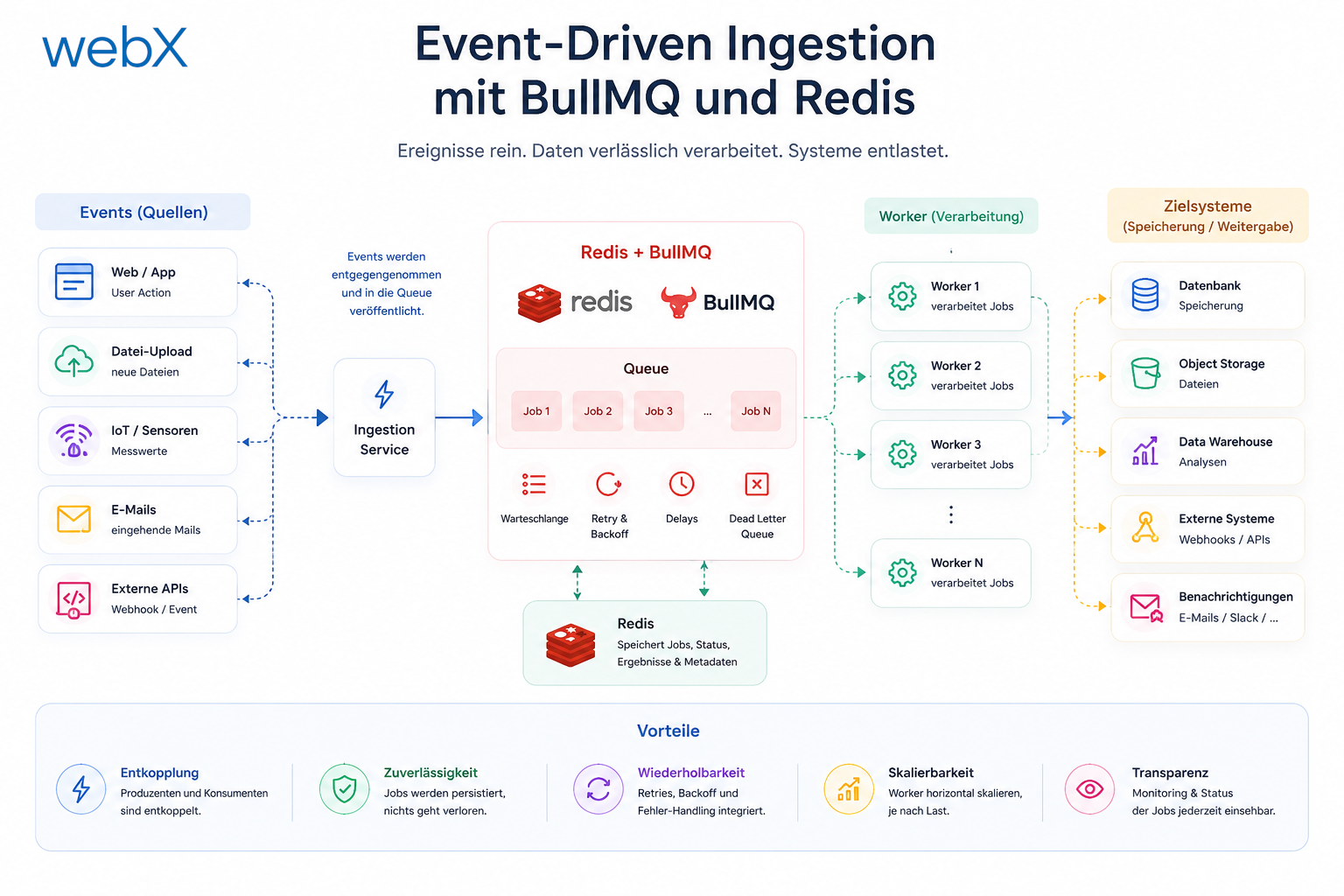
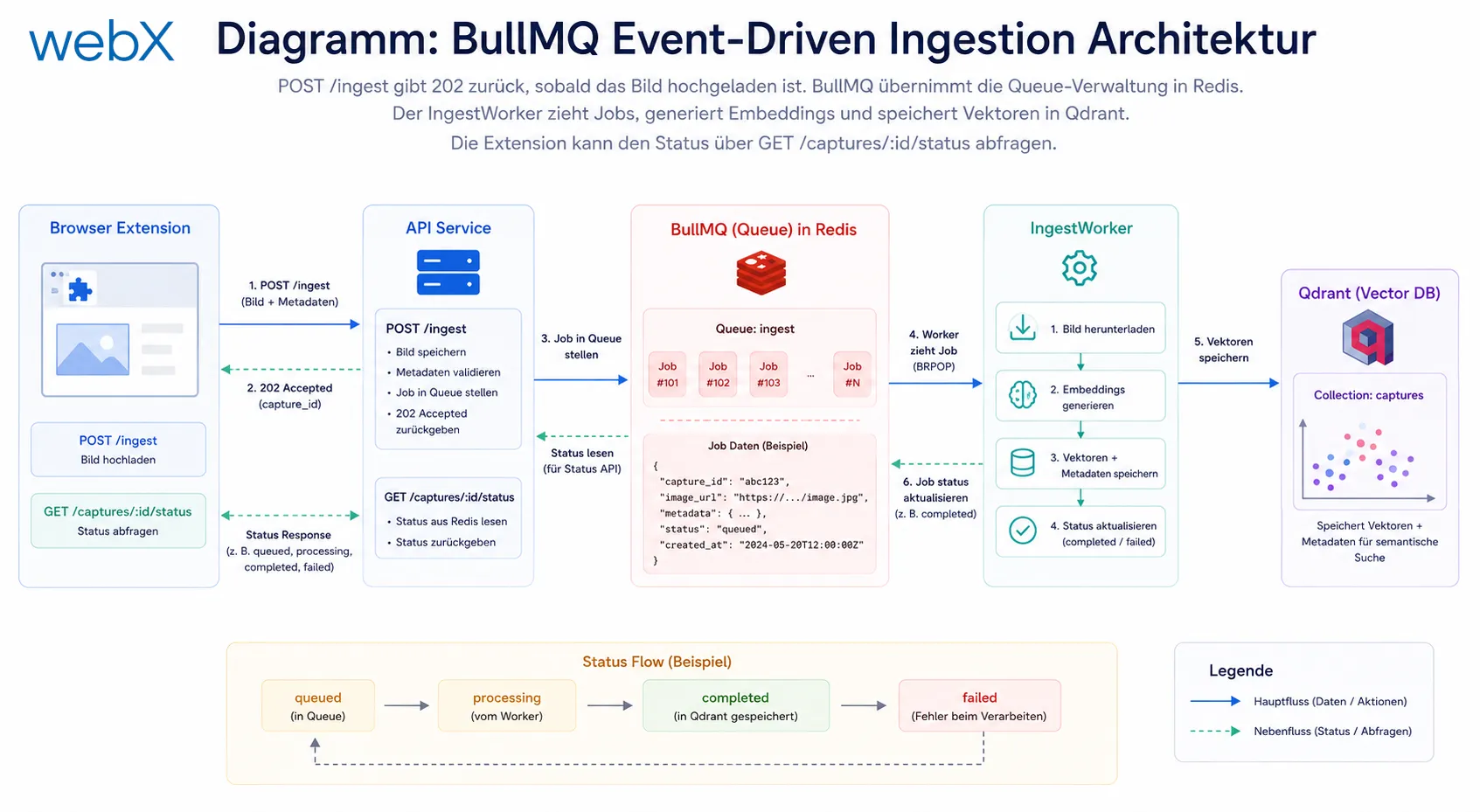 Abbildung: POST /ingest gibt 202 zurück, sobald das Bild hochgeladen ist. BullMQ übernimmt die Queue-Verwaltung in Redis. Der IngestWorker zieht Jobs, generiert Embeddings und speichert Vektoren in Qdrant. Die Extension kann den Status über GET /captures/:id/status abfragen.
Abbildung: POST /ingest gibt 202 zurück, sobald das Bild hochgeladen ist. BullMQ übernimmt die Queue-Verwaltung in Redis. Der IngestWorker zieht Jobs, generiert Embeddings und speichert Vektoren in Qdrant. Die Extension kann den Status über GET /captures/:id/status abfragen.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
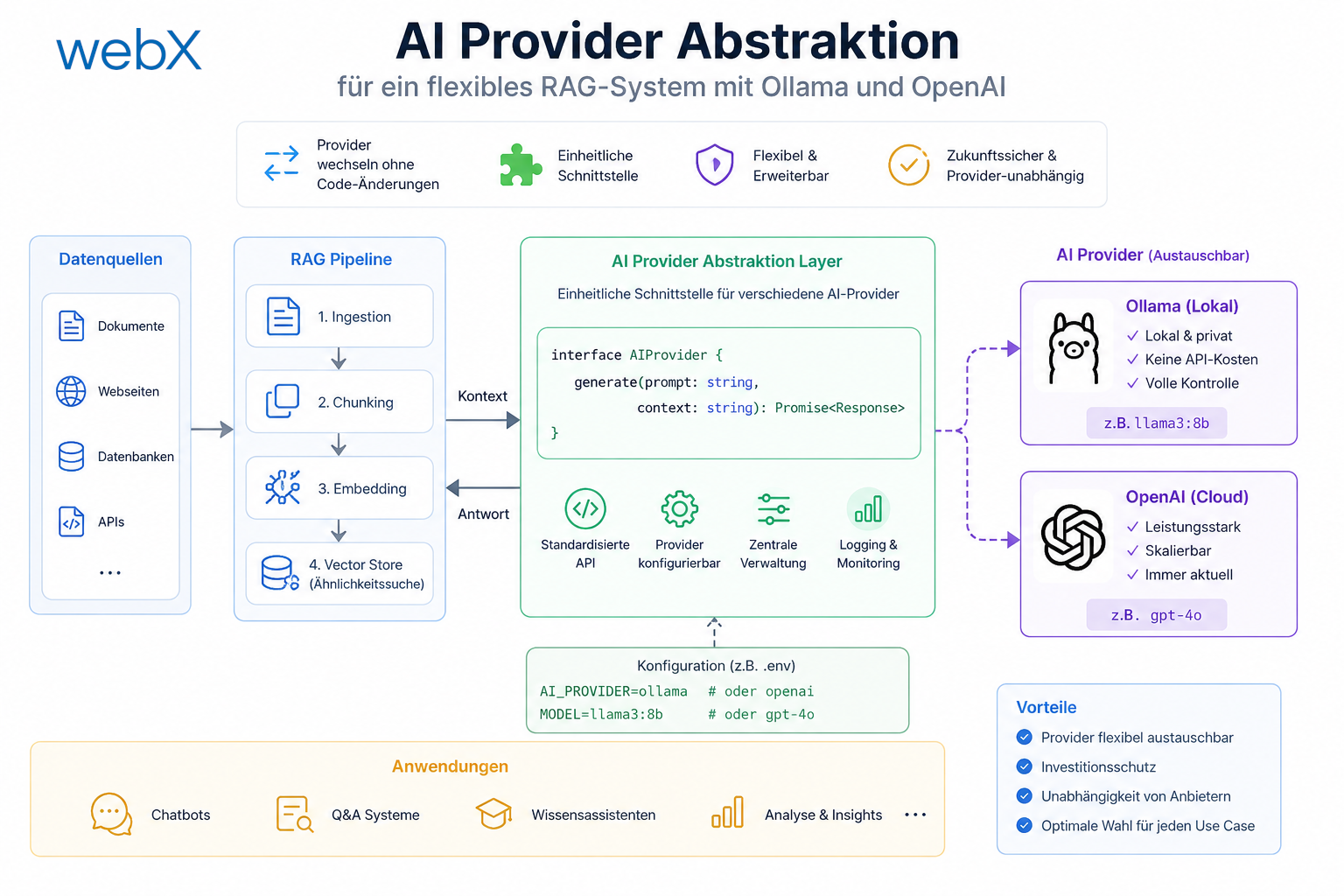
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: (dieser Artikel)
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
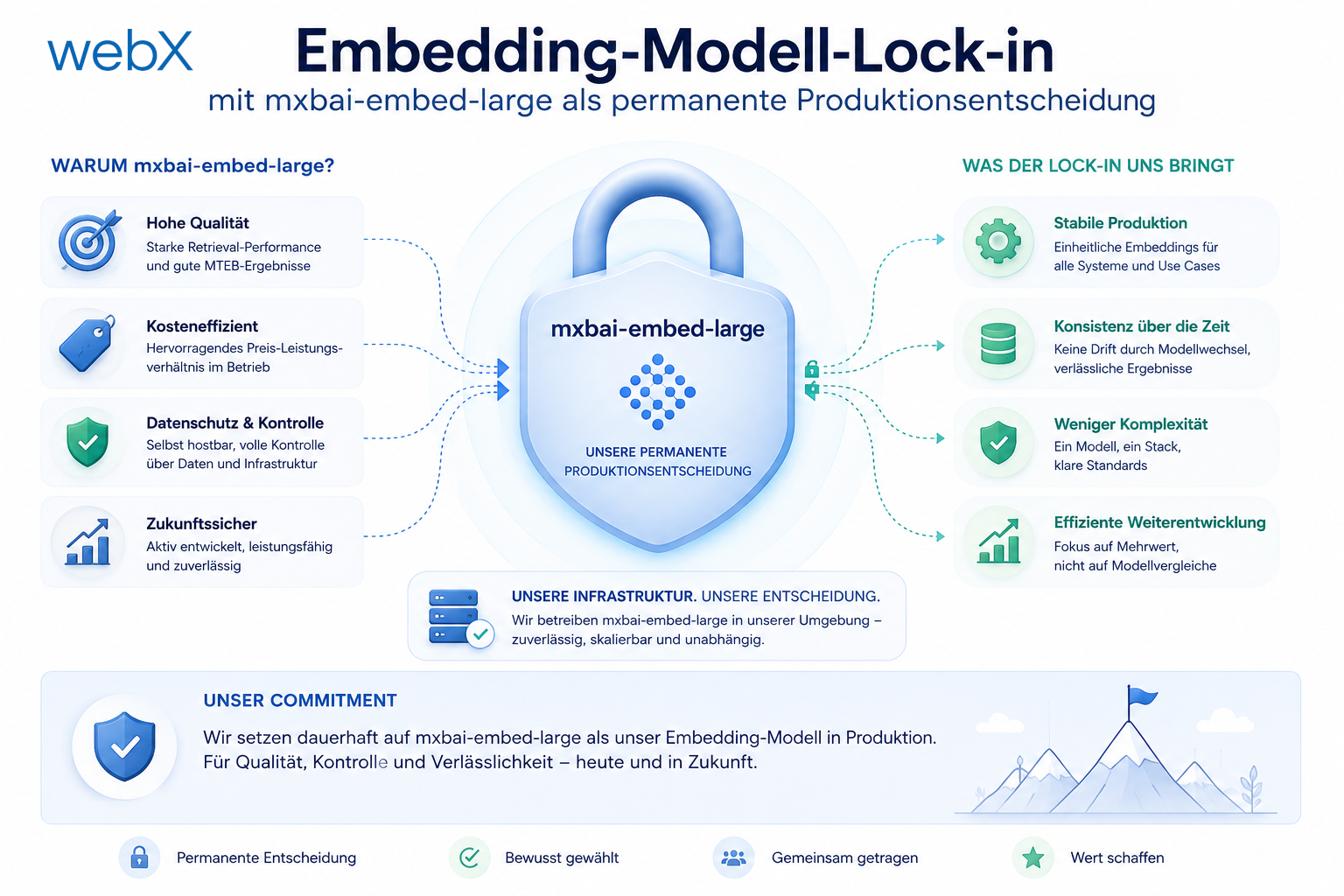
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du baust ein event-driven Backend mit BullMQ und Redis und steckst bei der Worker-Konfiguration oder der Fehlerbehandlung fest? Lass uns das gemeinsam einschätzen.