· David Göschel · Architektur · 5 minuten Lesezeit
Warum ich den Chunk in meinem RAG-System auf 1500 Tokens gesetzt habe
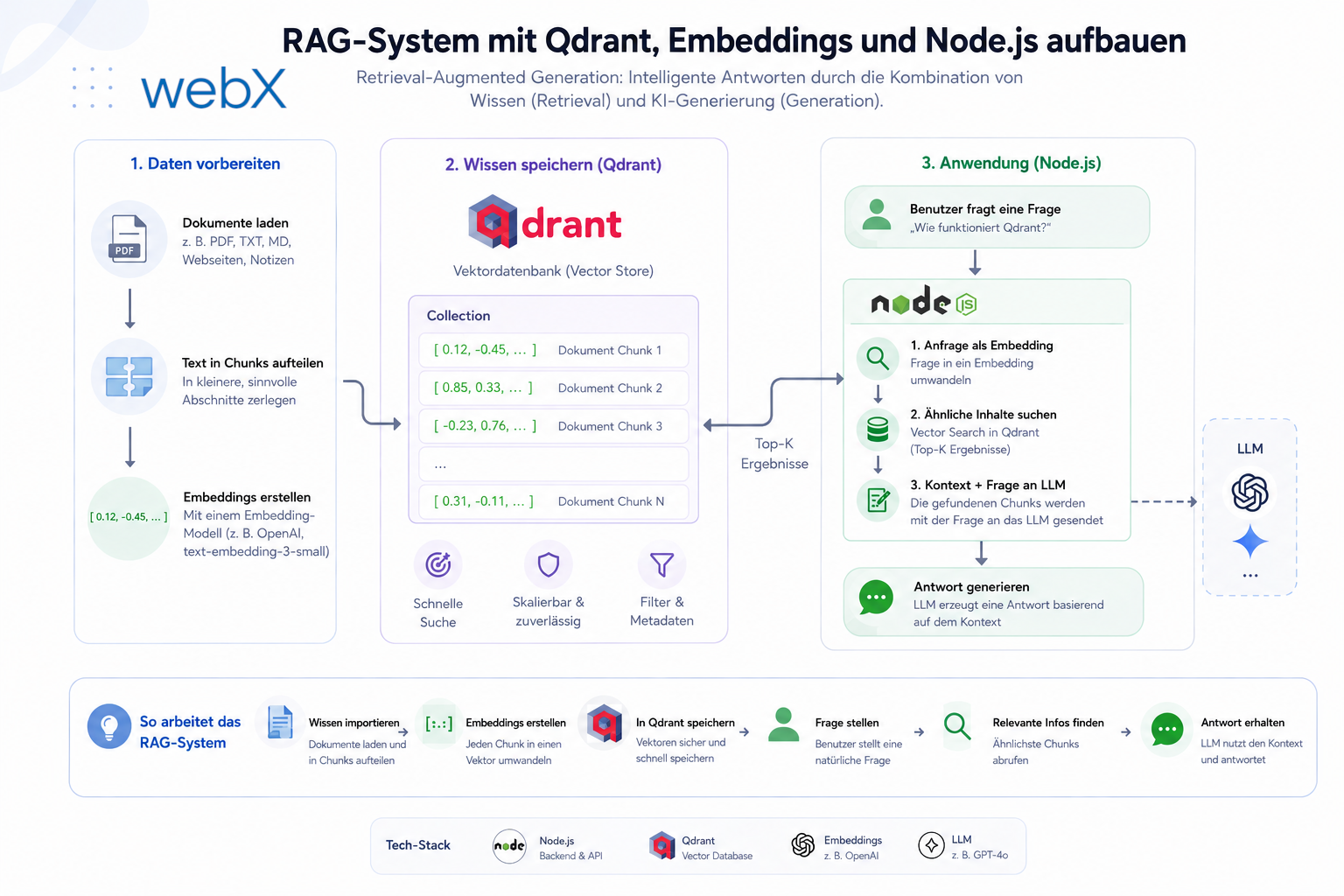
Die Migration auf bge-m3 brachte ein 8192 Tokens Limit. Dennoch habe ich das Chunk-Limit bewusst auf 1500 Tokens gesetzt, um die semantische Schärfe zu bewahren.

Inhalt
- Warum ich nicht bis an die Grenze von 8192 Tokens gegangen bin
- Warum 1500 Tokens die optimale Arbeitsgröße sind
- Was mir die neuen Ingest-Logs zeigen
- Wie ich die Entscheidung absichere
- Alle Artikel der Serie
Warum ich nicht bis an die Grenze von 8192 Tokens gegangen bin
Mit der Migration unseres Embedding-Modells von mxbai-embed-large auf BAAI/bge-m3 hat sich die technische Ausgangslage grundlegend geändert. Statt mickriger 512 Tokens steht uns nun ein gigantischer Kontextrahmen von bis zu 8192 Tokens zur Verfügung.
Auf dem Papier klingt das verlockend: Warum nicht einfach jeden noch so langen Instagram-Beitrag oder LinkedIn-Post am Stück einbetten, ohne sich jemals wieder Gedanken über Segmentierung machen zu müssen?
Die Antwort liegt in der Informationstheorie und der Suchpräzision (Retrieval-Quality). Wenn wir einen extrem langen Text in einen einzigen Vektor pressen, wird dieser Vektor zwangsläufig sehr grob und “verwaschen”. Ein einziger Vektor muss dann Dutzende verschiedene Aussagen und Nuancen gleichzeitig repräsentieren. Die semantische Schärfe geht verloren.
Warum 1500 Tokens die optimale Arbeitsgröße sind
Ich habe mich nach umfassenden Tests bewusst für eine konservative Chunk-Größe von 1500 Tokens (mit einem Overlap von 150 Tokens) entschieden. Das hat drei handfeste Gründe:
- Semantischer Fokus: Ein Chunk von maximal 1500 Tokens ist groß genug, um zusammenhängende Gedanken und Kontext vollständig zu erfassen, aber klein genug, um eine extrem hohe Vektordichte zu garantieren. Bei Suchanfragen treffen wir so punktgenau den relevanten Abschnitt.
- Praktische Abdeckung: Ein Großteil aller realen Captions, OCR-Texte und Metadaten von Instagram und sogar ausführlichen LinkedIn-Beiträgen liegt weit unter 1500 Tokens. Das bedeutet: In über 90% der Fälle wird der Text überhaupt nicht gesplittet, sondern wandert als einzelner, hochpräziser Vektor in die Datenbank.
- Absoluter Sicherheitsabstand: Mit einem Limit von 1500 Tokens bewegen wir uns meilenweit unter der physikalischen Grenze von 8192 Tokens des
bge-m3-Modells. Wir eliminieren jegliches Risiko von API-Überläufen komplett und behalten massiven Spielraum für zukünftige Metadaten-Erweiterungen.
Was mir die neuen Ingest-Logs zeigen
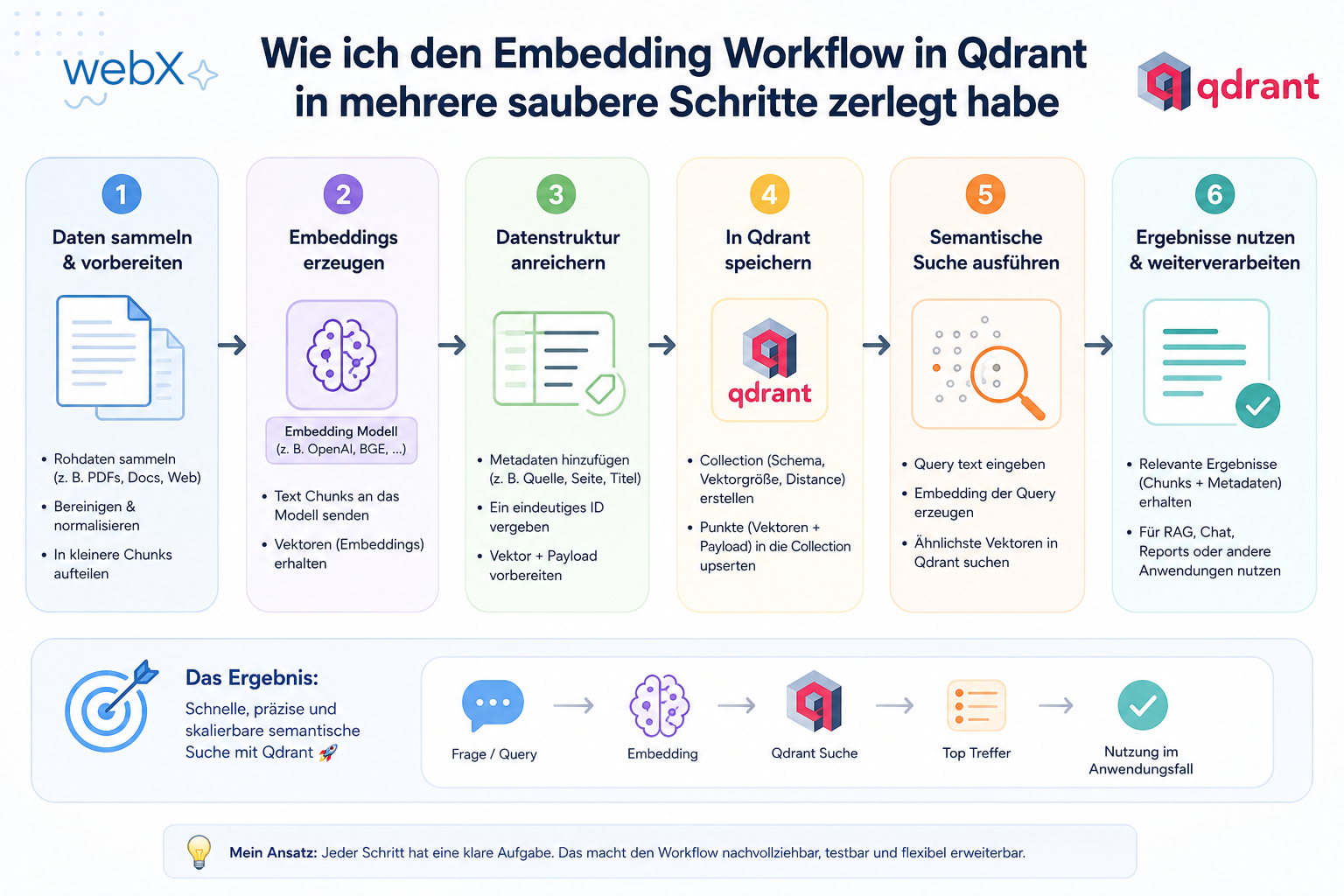
Um diese Entscheidung abzusichern, loggt der IngestWorker nun präzise die Token-Auslastung jedes einzelnen Chunks. Wir nutzen hierzu @xenova/transformers mit dem echten XLM-RoBERTa BPE Tokenizer des bge-m3-Modells im Node-Backend. Das garantiert absolute Übereinstimmung beim Zählen.
// Real-time worker log showing the chunking execution
[IngestWorker] captureId abc | tokens=2145 chunks=2
[IngestWorker] captureId abc | chunk 1/2 contentTokens=1498/1500 modelTokens=1500/8192 (ok) chars=6234
[IngestWorker] captureId abc | chunk 2/2 contentTokens=647/1500 modelTokens=649/8192 (ok) chars=2811Dieses Log beweist die Stabilität unseres Ansatzes: Die Chunks bleiben sauber partitioniert, der Tokenizer zählt fehlerfrei, und das Modell signalisiert entspanntes “ok”, da wir uns weit unter dem Limit bewegen.
Wie ich die Entscheidung absichere
Die Wahl von 1500 Tokens ist kein starrer, willkürlicher Wert, sondern eine bewusste Designentscheidung. Wir verknüpfen sie mit dem nativen Tokenizer im Backend-Code, um Drifts beim Zählen auszuschließen.
Zusammen mit der automatisierten Bereitstellung des Modells via Docker-Compose und der Einbettung im Worker haben wir ein hochgradig robustes Fundament gelegt.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: (dieser Artikel)
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du baust gerade ein ähnliches System und willst die gleiche Struktur für dein Projekt bewerten? Lass uns das gemeinsam einschätzen.