· David Göschel · Architektur · 5 minuten Lesezeit
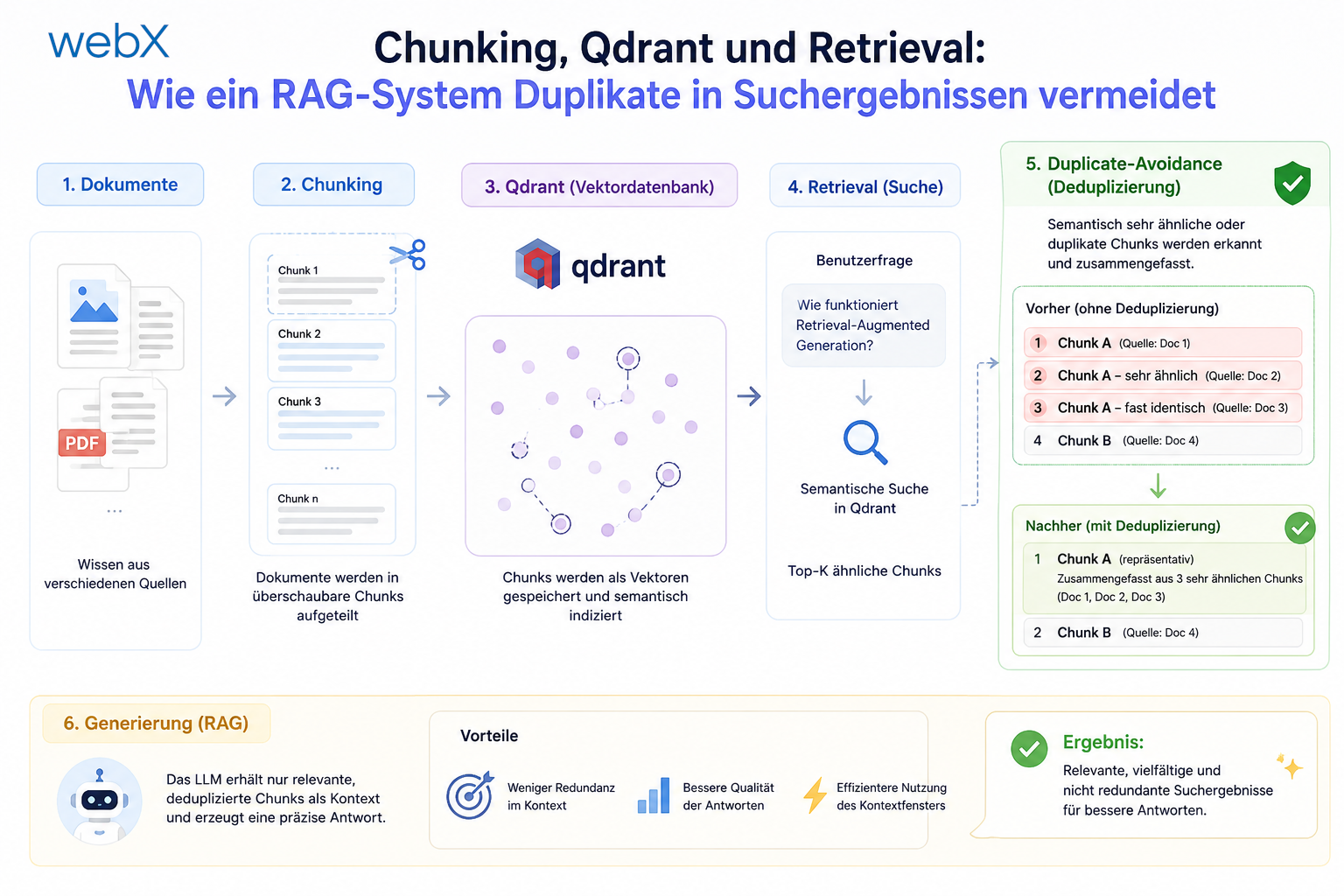
Chunking, Qdrant und Retrieval: Wie ein RAG-System Duplikate in Suchergebnissen vermeidet
Ich prüfe den neuen Pfad vom Worker bis zur Suche, damit ein langer Capture nicht nur verarbeitet wird, sondern im Ergebnis auch sauber als ein Treffer erscheint.
Inhalt
- Was ich bei der Verifikation sehen will
- Die Herausforderung bei der Suche (The Retrieval Challenge)
- Die Deduplizierungs-Strategie im Query-Pfad
- Was wir am Ende ablesen
- DSGVO Art. 17 Konformität auf Knopfdruck
- Alle Artikel der Serie
Was ich bei der Verifikation sehen will
Wenn wir einen geteilten Ablauf auf Herz und Nieren prüfen wollen, müssen wir drei klar getrennte Schichten im Auge behalten:
- Der Worker muss einen langen Quelltext zuverlässig in überlappende Token-Chunks zerlegen.
- Qdrant muss mehrere Punkte (Points) pro Capture-Datensatz aufnehmen können.
- Der Query-Pfad darf am Ende trotzdem nur maximal einen, perfekt passenden Treffer pro Capture zurückgeben.
Erst wenn diese drei Ebenen nahtlos zusammenspielen, haben wir ein robustes RAG-System. Vorher hatten wir die Diagnose gestellt und die Entscheidung für 1500 Tokens getroffen. Erst danach hatten wir die nötige Stabilität im Ingestion-Prozess, um das Zusammenspiel von Speicherung und Suche systematisch zu validieren.
Die Herausforderung bei der Suche (The Retrieval Challenge)
Sobald ein Capture in mehrere Chunks unterteilt ist, existieren in Qdrant mehrere Vektoren, die alle auf dieselbe physische Capture verweisen (captureId). Bei einer Ähnlichkeitssuche ist die Wahrscheinlichkeit hoch, dass Qdrant mehrere Chunks desselben Beitrags zurückgibt.
Ohne Gegenmaßnahmen würde die Suchergebnisliste mit Duplikaten oder Bruchstücken desselben Beitrags geflutet werden. Das vermindert die Ergebnis-Vielfalt drastisch und füllt den wertvollen Kontextrahmen unseres nachgelagerten LLMs mit redundantem Text.
Die Deduplizierungs-Strategie im Query-Pfad
Wir lösen dieses Problem elegant direkt in unserer Retrieval-Logik (retrieval.ts) auf dem Backend:
// Query deduplication logic based on captureId
const deduplicatedResults = results.reduce<StoredQueryResult[]>((acc, current) => {
const exists = acc.some((item) => item.payload.captureId === current.payload.captureId);
if (!exists) {
acc.push(current);
}
return acc;
}, []);Wir führen zuerst die Ähnlichkeitssuche in Qdrant aus (isoliert auf die userId des anfragenden Nutzers). Anschließend deduplizieren wir die zurückgegebenen Treffer programmgesteuert anhand ihrer captureId. Es verbleibt pro Capture nur derjenige Chunk, der den höchsten Cosine-Ähnlichkeits-Score zur Benutzeranfrage aufweist.
Was wir am Ende ablesen
Die End-to-End-Validierung belegt den Erfolg:
- Im Worker-Log sehen wir exakt die Anzahl der Tokens des Eingabetextes und die daraus resultierenden Chunks (z. B.
tokens=2145 chunks=2). - In Qdrant werden die Punkte sauber unter zufälligen RFC 4122 UUIDs mit allen notwendigen Minimal-Metadaten hinterlegt.
- In der API-Antwort der Suche (
POST /query) erhalten wir ein hochpräzises, dedupliziertes Ergebnis-Array. Jeder Treffer repräsentiert ein einzigartiges Capture, angereichert mit dem semantisch stärksten Textausschnitt für das LLM.
DSGVO Art. 17 Konformität auf Knopfdruck
Durch die Entscheidung, eine einzige Shared Collection mit einem Keyword-Index auf userId zu nutzen, profitiert auch der Löschprozess (Right to Erasure) enorm. Um alle Vektordaten eines Nutzers rückstandslos zu entfernen, müssen wir nicht mehr mühsam per-User Collections löschen. Ein einfacher Filter-Delete-Request in Qdrant löscht alle zugehörigen Punkte augenblicklich:
// Instant tenant erasure from shared collection
await client.delete(COLLECTION_NAME, {
filter: {
must: [{ key: "userId", match: { value: userId } }],
},
});Das ist DSGVO-Konformität in Höchstgeschwindigkeit, ohne operationalen Overhead.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
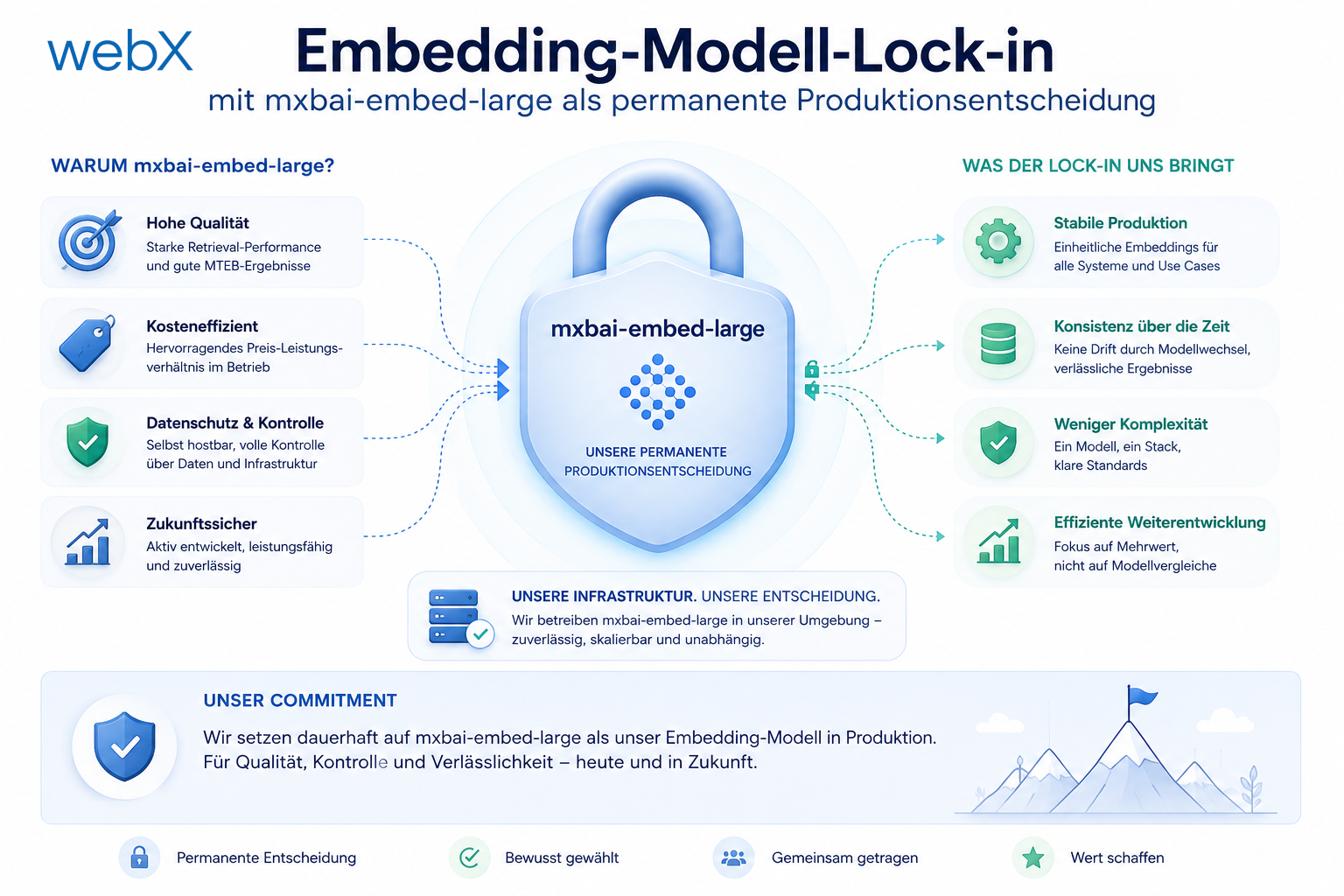
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
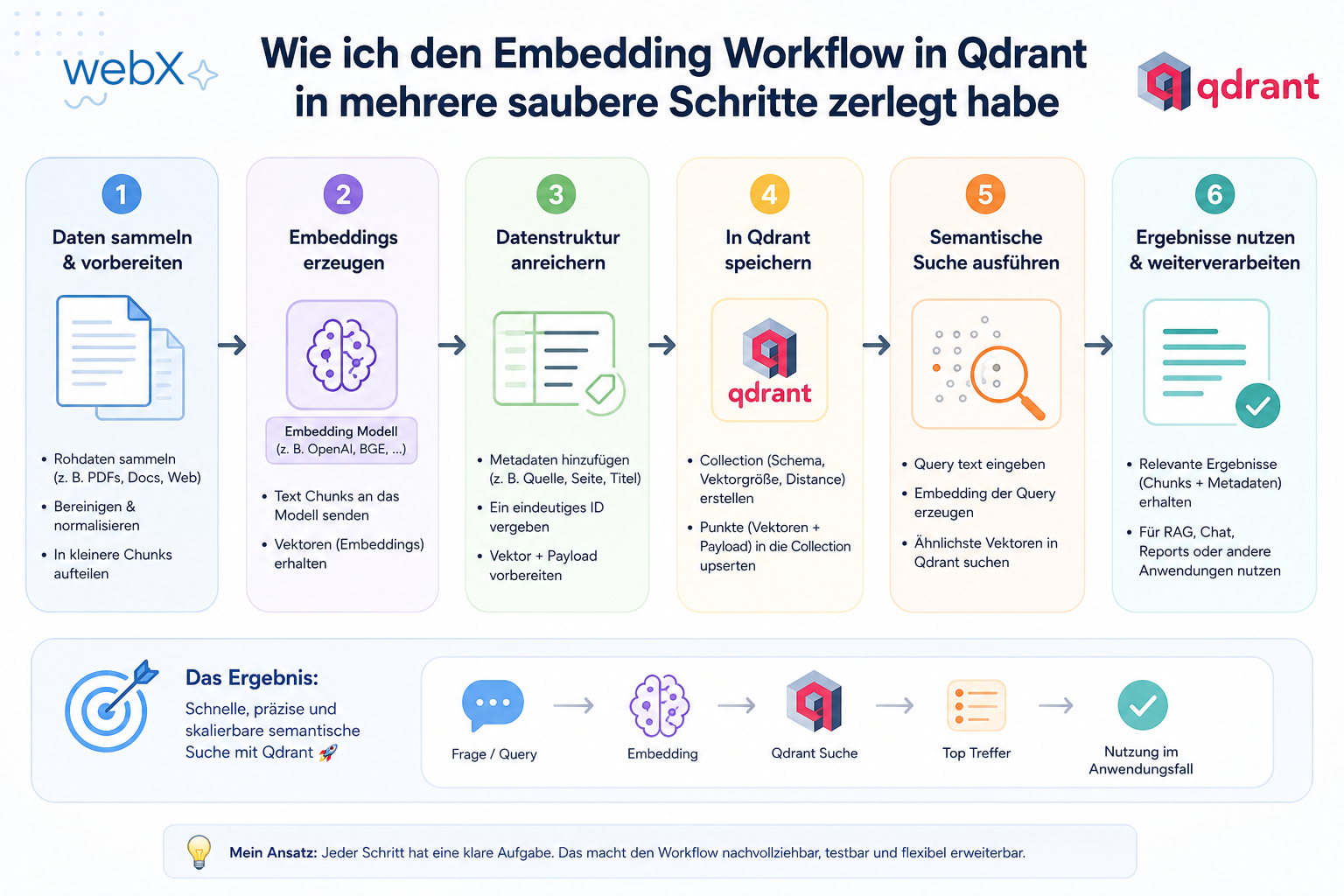
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: (dieser Artikel)
Du arbeitest gerade an einem ähnlichen RAG System und willst die gleiche Struktur für dein Projekt bewerten? Lass uns das gemeinsam einschätzen.