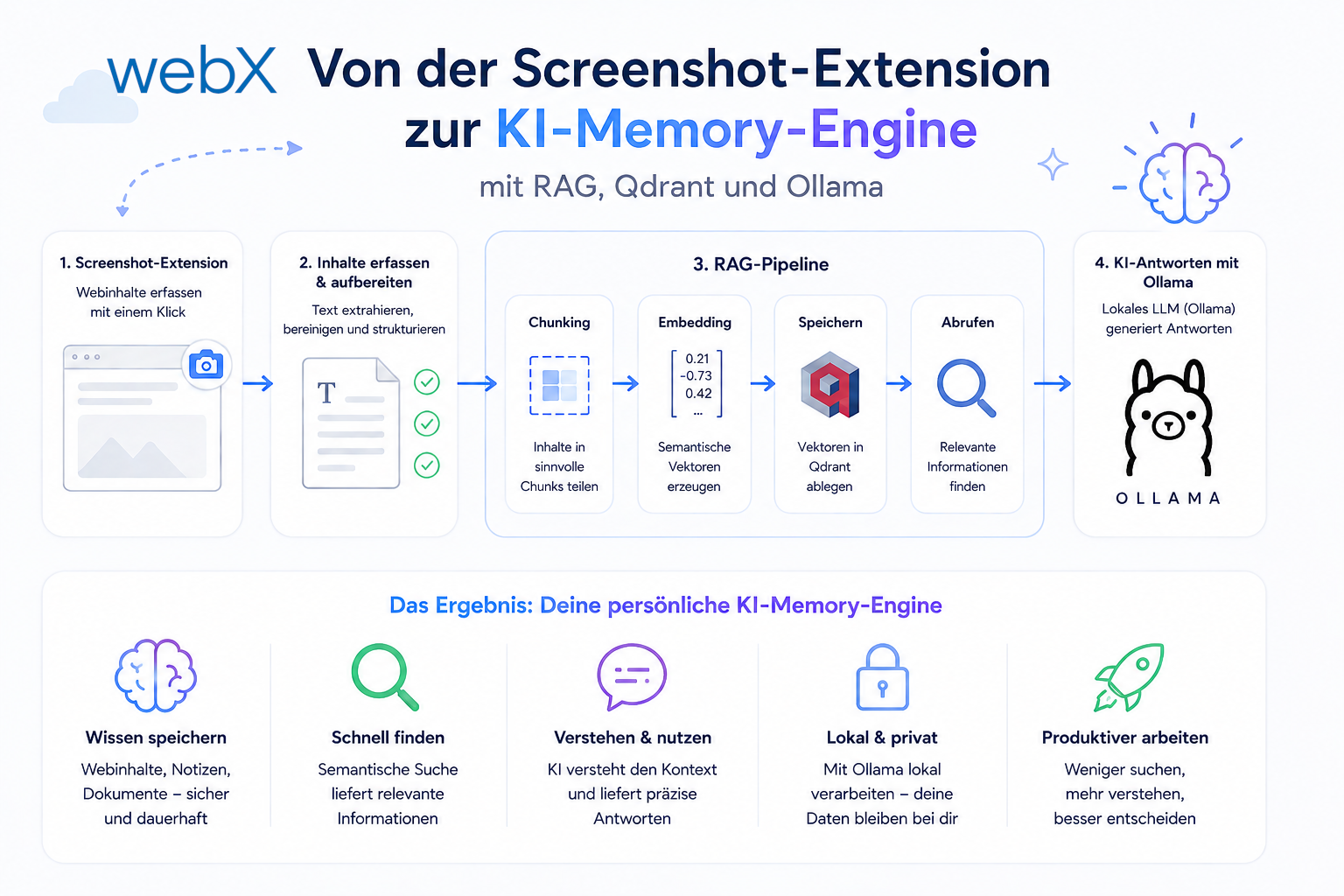
· David Göschel · Architektur · 7 minuten Lesezeit
Von der Screenshot-Extension zur KI-Memory-Engine mit RAG, Qdrant und Ollama
Eine Chrome Extension für Instagram-Metadaten war der Ausgangspunkt. Was folgte, war ein vollständiges RAG-System auf Basis von Qdrant, Ollama und TypeScript, das lokal läuft, cloud-ready ist und semantische Suche über erfasste Social-Media-Daten ermöglicht.
Inhalt
- Das Problem mit reinen Capture-Tools
- RAG als Lösung
- Das Ökosystem im Überblick
- Warum dieses Projekt in die Produktion geht
- Was dabei nicht sofort funktioniert hat
- Alle Artikel der Serie
Das Problem mit reinen Capture-Tools
Ich hatte eine Chrome MV3 Extension für ein Kunden gebaut. Sie macht genau das, was sie soll: Element hovern, Ctrl+Q drücken, Screenshot wird gemacht, zugeschnitten und an ein Backend geschickt. Mit Instagram-Metadaten. Mit DPR-Skalierung. Mit plattformspezifischen Payload-Strategien.
Technisch sauber. Funktional solide. Aber mit einer klaren Lücke.
Das Problem war nicht die Extension selbst. Das Problem war, was danach passiert. Die Daten landen in einem Backend. Aber sie sind dort nicht durchsuchbar. Kein Analyst kann fragen: „Welche Accounts haben in den letzten 30 Tagen am häufigsten Produkte aus dem Bereich Home & Living gepostet?” oder „Welche Caption-Strukturen performen bei Fashion-Accounts am stärksten?”
Das ist die technische Grenze von 90% aller Capture-Tools: Sie können aufnehmen. Aber nicht abrufen. Nicht semantisch suchen. Nicht erinnern.
RAG als Lösung
Was hier fehlte, war keine bessere Capture-Logik. Was fehlte, war eine Retrieval-Augmented Generation (RAG) Engine. Ein System, das:
- Texte und Metadaten in semantische Vektoren umwandelt (Embeddings)
- Diese Vektoren in einer Datenbank speichert, die Ähnlichkeiten versteht
- Bei einer natürlichsprachlichen Anfrage die relevantesten Einträge findet
- Daraus eine zusammenhängende Antwort über ein Large Language Model generiert
RAG ist 2026 keine experimentelle Technologie mehr. Die Komponenten sind produktionsreif, gut dokumentiert und lassen sich vollständig lokal betreiben, ohne Cloud-Abhängigkeiten und ohne laufende Kosten.
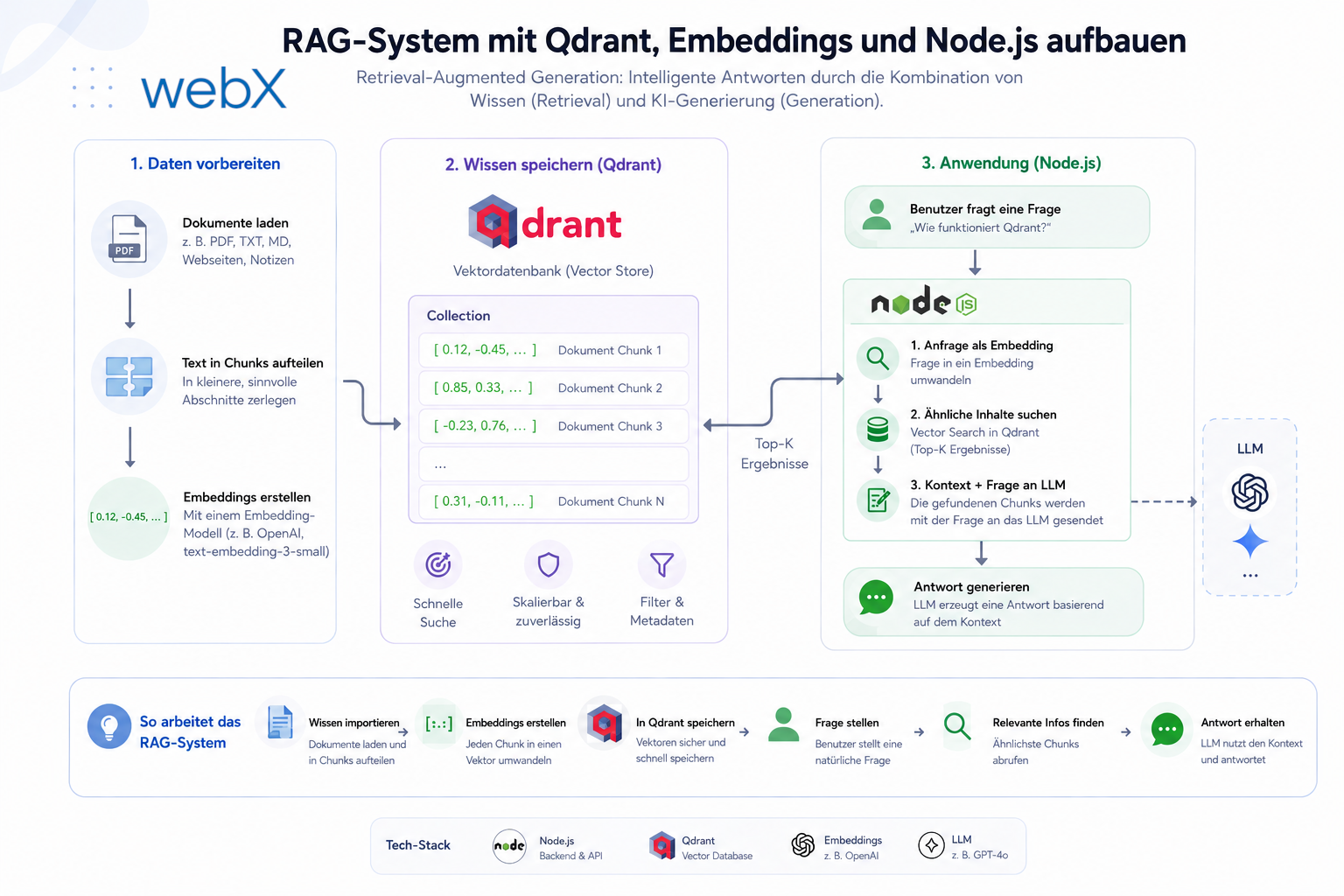
 Abbildung: Die sechs Schritte eines RAG-Systems: Der eingehende Text wird in einen Vektor umgewandelt, in Qdrant nach ähnlichen Einträgen gesucht, und das Ergebnis als Kontext an das Sprachmodell übergeben, das daraus eine verständliche Antwort formuliert.
Abbildung: Die sechs Schritte eines RAG-Systems: Der eingehende Text wird in einen Vektor umgewandelt, in Qdrant nach ähnlichen Einträgen gesucht, und das Ergebnis als Kontext an das Sprachmodell übergeben, das daraus eine verständliche Antwort formuliert.
Das Ökosystem im Überblick
Was dabei entstanden ist, nenne ich Local Insight: ein vollständiger Memory-Stack auf Basis von fünf Komponenten.
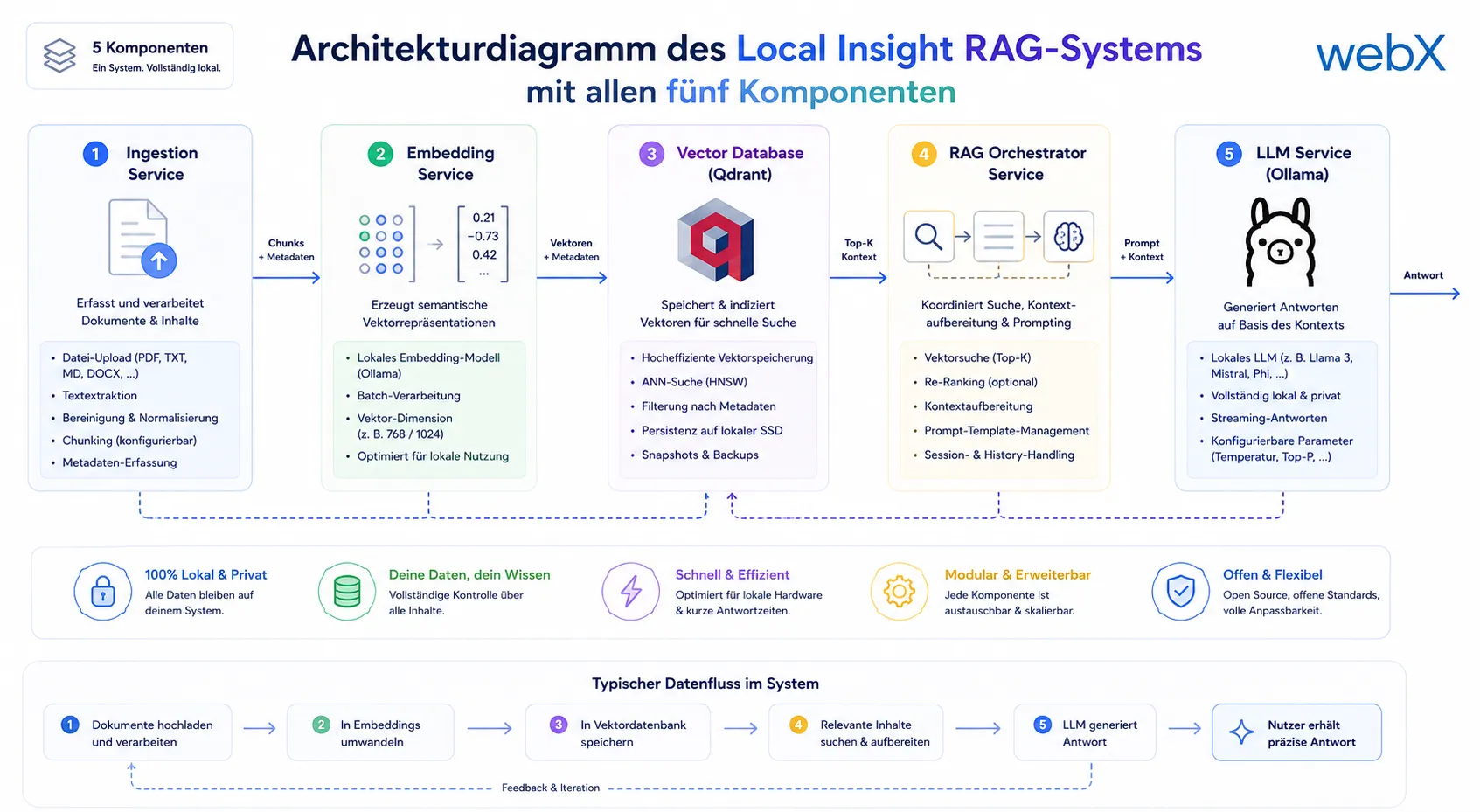 Abbildung: Alle fünf Komponenten des Local-Insight-RAG-Systems im Zusammenspiel: Die Ingestion verarbeitet Inhalte, das Embedding-Modell erzeugt Vektoren und Qdrant speichert sie semantisch. Der Retriever liefert relevante Kontextdaten an Ollama, das daraus lokal die finale Antwort generiert.
Abbildung: Alle fünf Komponenten des Local-Insight-RAG-Systems im Zusammenspiel: Die Ingestion verarbeitet Inhalte, das Embedding-Modell erzeugt Vektoren und Qdrant speichert sie semantisch. Der Retriever liefert relevante Kontextdaten an Ollama, das daraus lokal die finale Antwort generiert.
1. Chrome MV3 Extension (TypeScript, Vite, @crxjs) Die Extension wurde um einen konfigurierbaren Endpunkt erweitert. Sie kommuniziert jetzt mit dem RAG-Backend statt nur mit einem simplen File-Upload-Endpoint. Wie die drei isolierten Laufzeitkontexte der Extension sauber miteinander kommunizieren, beschreibe ich im Artikel zur Chrome Extension MV3 Architektur.
2. Node.js/Express Backend (TypeScript) Das zentrale Element des Systems. Es empfängt den Screenshot-Payload, extrahiert einbettbaren Text aus den Instagram-Metadaten, generiert einen 768-dimensionalen Vektor über die AI-Provider-Abstraktion und schreibt alles nach Qdrant.
3. Qdrant (Vektordatenbank, Docker) Qdrant ist eine speziell für Vektoren optimierte Datenbank. Cosine-Ähnlichkeit ist out of the box verfügbar, die Performance ist auch bei zehntausenden gespeicherten Punkten stabil. Kein externer Dienst, keine Cloud-Abhängigkeit. Den vollständigen Aufbau des RAG-Systems mit Qdrant und Embeddings zeige ich im Artikel zur Vektordatenbank und dem RAG-System-Aufbau.
4. AI Provider (Ollama lokal oder OpenAI) Die architektonisch wichtigste Entscheidung des gesamten Projekts: kein direkter Vendor-Lock-in. Eine Abstraktionsschicht über ein AIProvider-Interface erlaubt es, mit einer einzigen Umgebungsvariable zwischen lokalem nomic-embed-text über Ollama und text-embedding-3-small über OpenAI zu wechseln. Warum das kein Over-Engineering ist und wie das Interface konkret aussieht, erkläre ich im Artikel zur AI Provider Abstraktion.
5. React Dashboard (Vite, Tailwind, shadcn/ui) Die Oberfläche für Suchanfragen. Natürlichsprachliche Eingabe, KI-generierte Antwort, visuelle Result Cards mit Screenshot-Thumbnails und Metadaten.
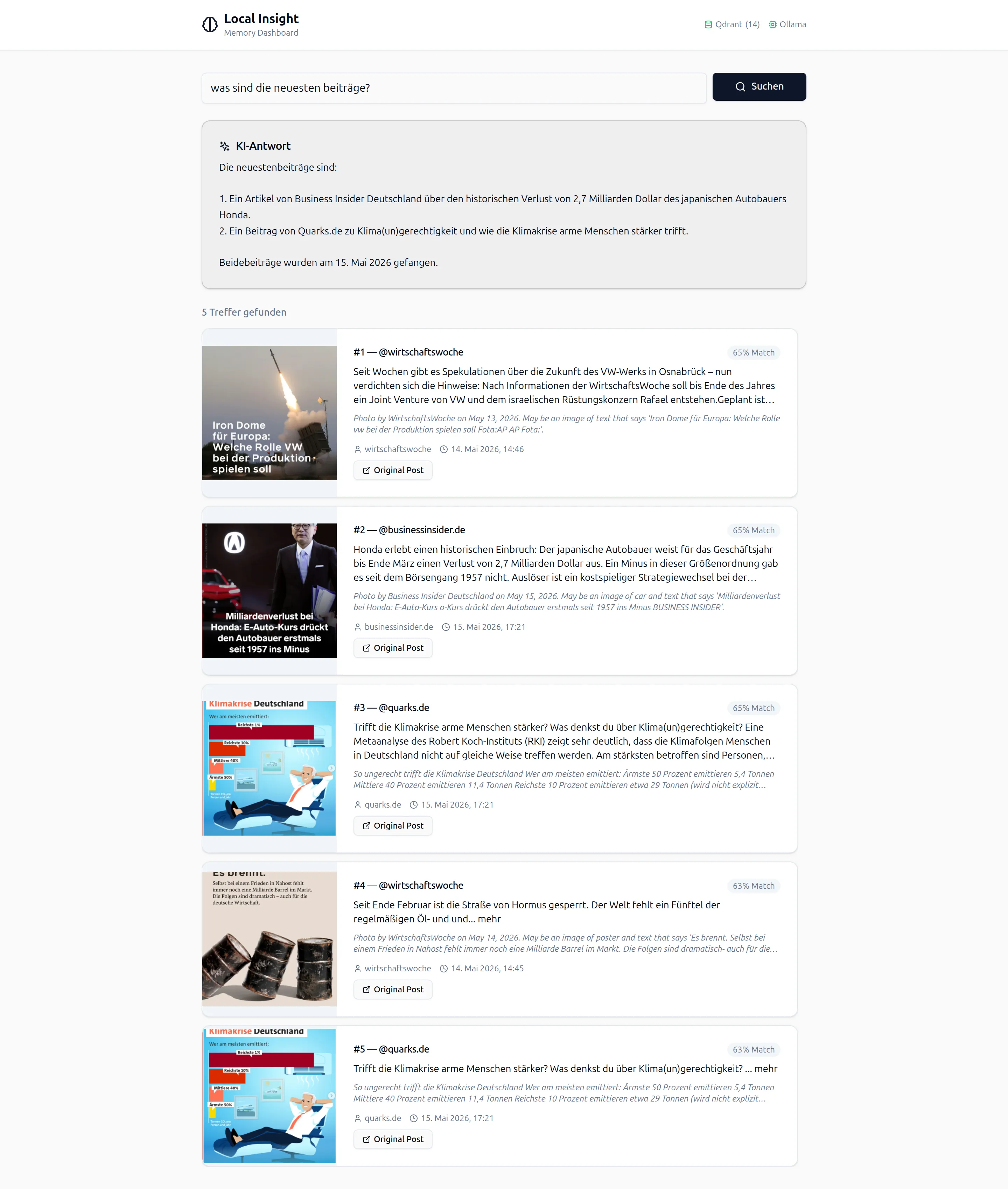 Abbildung: Das React Dashboard in der Praxis: Eine Analyst-Frage wird eingegeben, das System durchsucht die gespeicherten Instagram-Daten semantisch und liefert eine strukturierte Antwort mit den relevantesten Treffern.
Abbildung: Das React Dashboard in der Praxis: Eine Analyst-Frage wird eingegeben, das System durchsucht die gespeicherten Instagram-Daten semantisch und liefert eine strukturierte Antwort mit den relevantesten Treffern.
Warum dieses Projekt in die Produktion geht
Den Ausgangspunkt lieferte ein Kundenprojekt im Bereich Open Source Intelligence & Risikofrüherkennung. Für diesen Kunden habe ich eine Chrome Extension entwickelt, mit der Analysten direkt im Browser Instagram-Posts erfassen und deren Metadaten strukturiert an ein Backend übertragen können.
Beim Aufbau dieser Extension hat sich eine Frage fast von selbst gestellt: Was passiert eigentlich mit den gesammelten Daten? Sie landen im Backend. Aber sie sind dort nicht durchsuchbar, nicht vergleichbar, nicht auswertbar.
Das RAG-System ist meine eigene Antwort auf diese Frage. Kein Kundenprojekt, sondern ein System, das ich auf Basis dieser Erfahrung selbst plane und in naher Zukunft produktiv einsetzen werde. Die Chrome Extension ist die Datenquelle. Das RAG-System ist die Intelligenz dahinter.
Wer ein RAG-System für reale Analyst-Workflows baut, versteht Vektordatenbanken, Embedding-Modelle und LLM-Inferenz nicht nur theoretisch. Diese Erfahrung fließt direkt in Projekte ein, in denen semantische Suche oder KI-gestützte Datenauswertung gefragt ist.
Was dabei nicht sofort funktioniert hat
Der Weg zu einem funktionierenden RAG-System ist genauso lehrreich wie das Ergebnis selbst.
Problem 1: tsconfig.json und Vite Die Extension nutzte "module": "Node16", was für Node.js-Projekte korrekt ist, aber mit Vite als Bundler nicht funktioniert. Vite erwartet "moduleResolution": "bundler". Das Ergebnis waren neun TypeScript-Fehler auf einmal, alle wegen fehlender .js-Extensions in Importen. Wie dieser Konfigurationskonflikt entsteht und in zwei Minuten behoben wird, zeige ich im Artikel zum tsconfig moduleResolution Fehler mit Vite.
Problem 2: Ollama nicht erreichbar Der erste docker-compose up lieferte sofort einen Fehler: Ollama is not reachable. Ollama war in der Konfiguration referenziert, lief aber weder lokal noch als Container. Die Entscheidung, Ollama vollständig in Docker zu containerisieren, hat die gesamte Deployment-Strategie verändert. Die Abwägung zwischen lokalem Ollama und dem Docker-Ansatz beschreibe ich im Artikel zur Ollama lokal vs. Docker Entscheidung.
Problem 3: Manueller Setup-Schritt nach jedem Start Nach dem ersten erfolgreichen Start war das System lauffähig. Aber es brauchte noch einen manuellen docker exec-Schritt, um das Ollama-Modell zu laden. Das war ein Reibungspunkt, der sich nicht ignorieren ließ. Wie aus diesem Problem ein automatisiertes Entrypoint-Setup wurde, zeige ich im Artikel zum Ollama Auto-Pull Entrypoint.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: (dieser Artikel)
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
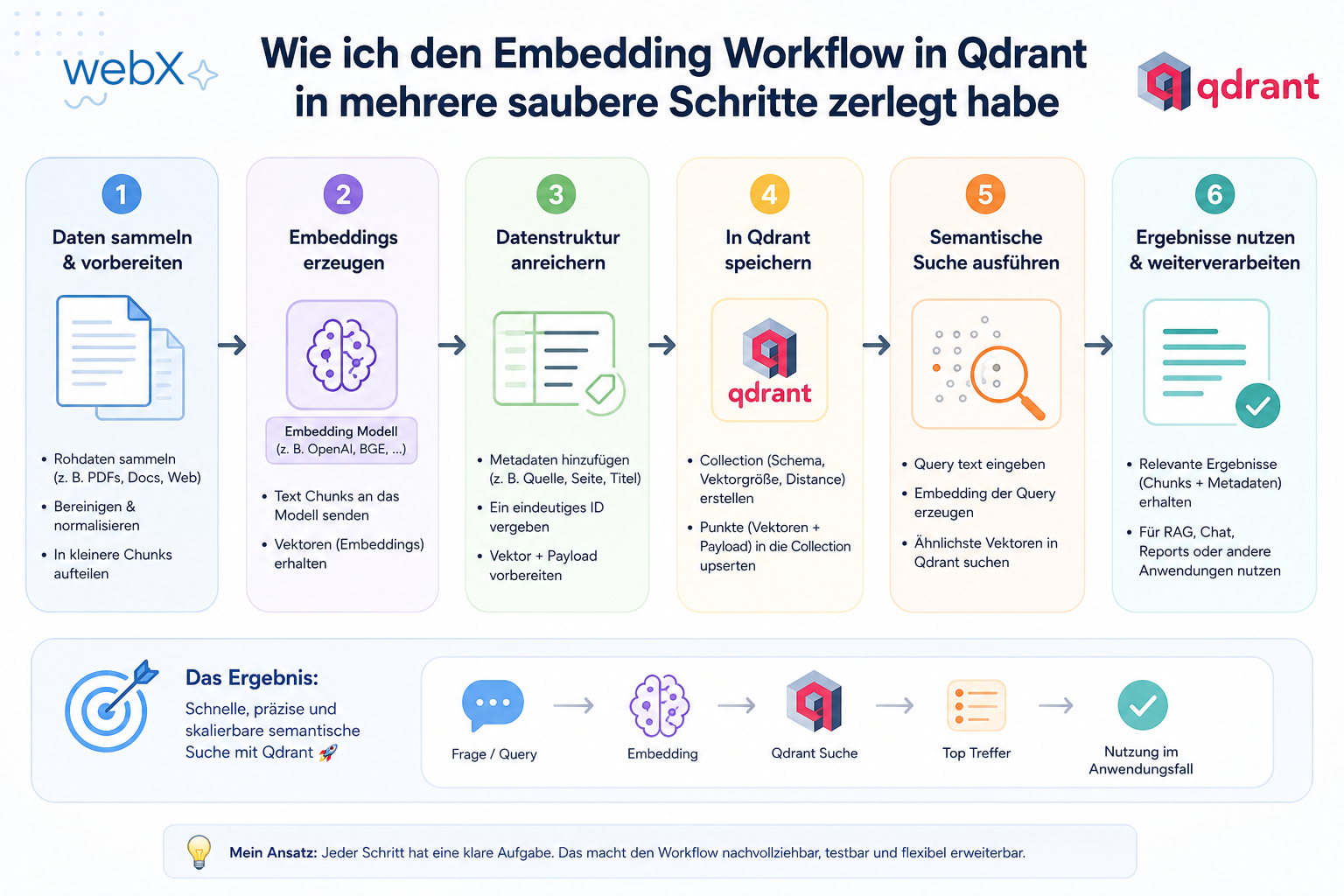
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du arbeitest an einem Power Pages Portal und überlegst, ob semantische Suche oder KI-gestütztes Dokumenten-Retrieval für deine Nutzer sinnvoll ist? Lass uns das gemeinsam einschätzen.