· David Göschel · Webentwicklung · 8 minuten Lesezeit
Backend Code Review vor dem Launch mit sechs behobenen Problemen
Vor dem Go-Live habe ich das Backend noch einmal vollständig durchgelesen. Sechs konkrete Probleme gefunden, alle behoben. Hier ist, was ich wo gefunden habe und warum es jeweils wichtig war.

Inhalt
- Warum ich das Backend nochmal gelesen habe
- Problem 1 mit S3Client als Wegwerfinstanz
- Problem 2 mit VECTOR_SIZE als hardcodierte Konstante
- Problem 3 mit Admin-PAT bei jedem Request neu einlesen
- Problem 4 mit totem Code im Ternary-Operator
- Problem 5 mit as any und falschem Label
- Problem 6 mit Import über einen Shim
- Was schon gut war
- Was noch offen ist
- Alle Artikel der Serie
Warum ich das Backend nochmal gelesen habe
Der Stack läuft. TypeScript kompiliert. Die Features sind implementiert. Aber zwischen “läuft lokal” und “geht in Produktion” liegt eine Lücke: Code, der unter Last, mit echten Nutzerdaten und ohne direkten Debugging-Zugriff funktionieren muss.
Ich habe mir drei Stunden genommen, die Backends-Dateien systematisch durchzulesen, ohne etwas zu ändern. Das Ziel war nicht, Features zu bauen, sondern Stellen zu finden, die in Produktion Probleme verursachen würden.
Ich habe sechs konkrete Probleme gefunden. Alle sind behoben.
Problem 1 mit S3Client als Wegwerfinstanz
In blob-storage.ts gab es Funktionen wie uploadScreenshot, getPresignedUrl und deleteObject. Jede Funktion begann mit:
// S3 client was re-created on every function call
const client = new S3Client({
endpoint: process.env.S3_ENDPOINT,
region: process.env.AWS_REGION ?? "auto",
credentials: { ... },
});Das bedeutet: Jeder API-Call zum Backend, der S3 berührt, erstellte eine neue S3Client-Instanz. Der Client baut intern einen HTTP-Connection-Pool auf. Dieser Pool wurde nach jedem Aufruf weggeworfen.
Unter Last bedeutet das: viele TCP-Verbindungen, die aufgebaut und sofort wieder geschlossen werden, statt eine bestehende Verbindung wiederzuverwenden. Und wenn die Umgebungsvariablen fehlen, wirft der Konstruktor beim ersten Request, nicht beim Start.
Die Lösung ist ein Lazy-Singleton:
// Module-level variables, initialized on first use
let _client: S3Client | null = null;
let _presignClient: S3Client | null = null;
function getClient(): S3Client {
if (!_client) {
_client = new S3Client({ /* config */ });
}
return _client;
}Die Instanz wird beim ersten Aufruf einmalig erstellt. Alle weiteren Aufrufe bekommen dieselbe Instanz. Die Verbindungen im Pool bleiben offen.
Problem 2 mit VECTOR_SIZE als hardcodierte Konstante
In qdrant.ts stand:
// Hardcoded — env var VECTOR_SIZE had no effect
const VECTOR_SIZE = 768;In docker-compose.yml war gleichzeitig VECTOR_SIZE=768 als Umgebungsvariable gesetzt. Das war eine stille Inkonsistenz: Wer den Wert in der Umgebungsvariable änderte, würde nichts merken, bis Qdrant beim Upsert mit einem Dimensionsfehler antwortet.
Wenn ein Embedding-Modell 1536 Dimensionen liefert (wie text-embedding-3-small von OpenAI), aber die Collection mit 768 angelegt wurde, schlägt jeder Speicherversuch still fehl oder wirft einen unverständlichen Fehler.
// Read from environment with safe fallback
const VECTOR_SIZE = parseInt(process.env.VECTOR_SIZE ?? "768", 10);Jetzt kontrolliert die Umgebungsvariable tatsächlich den Wert.
Problem 3 mit Admin-PAT bei jedem Request neu einlesen
In account.ts gibt es einen DELETE /account-Endpoint für DSGVO Art. 17 (Recht auf Löschung). Er benötigt einen Zitadel-Admin-PAT, um die Identität des Nutzers in Zitadel zu löschen.
Der ursprüngliche Code rief bei jedem Request eine Funktion auf, die die PAT-Datei vom Filesystem liest:
// Original: file system read on every DELETE request
router.delete("/", authMiddleware, async (req, res) => {
const pat = await getAdminPat(); // reads file each time
// ...
});Bei wenigen Anfragen pro Tag ist das irrelevant. Bei hundert gleichzeitigen Anfragen liest das Backend hundertmal dieselbe Datei. Das Filesystem ist schnell, aber es ist unnötige Arbeit und signalisiert, dass niemand über den Lebenszyklus des Werts nachgedacht hat.
Der PAT ändert sich nicht zur Laufzeit. Er gehört einmalig beim Start geladen:
// Cached at module load, not per request
let _adminPat: string | null = null;
async function loadAdminPat(): Promise<string> {
if (_adminPat) return _adminPat;
const patPath = process.env.ZITADEL_ADMIN_PAT_PATH ?? "/run/secrets/zitadel_admin_pat";
_adminPat = (await fs.readFile(patPath, "utf-8")).trim();
return _adminPat;
}Der erste Call beim Modulstart liest die Datei, jeder weitere gibt den gecachten Wert zurück.
Problem 4 mit totem Code im Ternary-Operator
Zwei Stellen im Code hatten einen Ternary-Operator, bei dem eine Bedingung nie eintreten konnte.
In account.ts beim Export-Endpoint:
// Dead branch: items was always an array at this point
const records = items ? items.map(...) : [];items war zu diesem Zeitpunkt immer ein Array, nie null oder undefined. Der else-Zweig war toter Code.
In query.ts beim Aufbau des LLM-Kontexts:
// Dead branch: platform was narrowed to "generic" at this point
const context = platform === "instagram"
? buildInstagramContext(metadata)
: buildGenericContext(metadata); // always this branchAn dieser Stelle im Code war platform durch TypeScript bereits auf "generic" eingeschränkt. Der Instagram-Zweig konnte nie erreicht werden.
Toter Code in produktionsnahem Code ist ein Warnsignal. Er täuscht vor, dass etwas passieren kann, was nie passiert. Er erschwert das Lesen und kann spätere Refactorings in die falsche Richtung lenken. Beide Stellen wurden vereinfacht.
Problem 5 mit as any und falschem Label
In query.ts gab es einen Block, der für generische Webseiten (also nicht Instagram) einen Kontext für das LLM aufbaute:
// Wrong: cast to any and labelled as Instagram
const meta = metadata as any;
const contextString = `Originally posted on Instagram at ${meta.timestampISO}`;Zwei Probleme: Erstens, GenericWebPagePayload.metadata hat kein Feld timestampISO. Der Cast auf any versteckte diesen Typfehler. Zweitens, der Text sagte “Originally posted on Instagram” für jede beliebige Webseite.
Das war ein Fall, wo der Code aus dem Instagram-Pfad kopiert und angepasst wurde, aber die Anpassung unvollständig war. Das LLM hätte für jeden gespeicherten Link eine falsche Quelle angezeigt.
// Typed access, no cast, correct label
const meta = metadata as GenericWebPagePayload["metadata"];
const contextString = [
`Page title: ${meta.pageTitle ?? "unknown"}`,
`Page URL: ${meta.pageUrl ?? "unknown"}`,
].join("\n");Kein as any, keine falsche Beschriftung, korrekte Felder aus dem Typ.
Problem 6 mit Import über einen Shim
In query.ts stand:
import { generateEmbedding } from "../services/ollama";ollama.ts war eine Datei, die nur re-exportierte:
// ollama.ts — misleading backward-compat shim
export { generateEmbedding } from "./ai-provider";Das war historisch gewachsen: Die Funktion war ursprünglich in ollama.ts, dann in die abstraktere ai-provider.ts verschoben worden, und ollama.ts blieb als Shim. Der Import in query.ts suggerierte, dass die Funktion direkt mit Ollama zusammenhing, was seit dem Wechsel auf ai-provider.ts nicht mehr stimmte.
Der Shim wurde entfernt. query.ts importiert direkt aus ai-provider.ts. Der Code beschreibt jetzt korrekt, was er tatsächlich nutzt.
Was schon gut war
Nicht alles brauchte Arbeit. Einige Teile des Backends waren schon in gutem Zustand:
Das Event-Driven-Muster für den Ingest-Prozess über BullMQ ist sauber. Jobs werden enqueued und von einem Worker abgearbeitet. Fehler enden im failed-Status, nicht in einem stillen Datenverlust.
Die Qdrant-Abstraktion in qdrant.ts isoliert alle Vektordatenbank-Operationen hinter klaren Funktionen. Der Rest des Codes weiß nichts von Qdrant-internen Konzepten.
Der AI-Provider-Abstraktions-Layer (ai-provider.ts) trennt sauber zwischen Ollama lokal und OpenAI in Produktion. Das Switching passiert über eine Umgebungsvariable, nicht über verzweigten Code im Query-Handler.
Was noch offen ist
Zwei Probleme habe ich dokumentiert, aber noch nicht behoben:
Rate Limiting auf POST /query fehlt. Jeder Request triggert Embedding und LLM-Call. Ein einzelnes Skript kann den API-Key leerlaufen lassen.
Der DELETE /account-Endpoint läuft sequenziell durch BullMQ, Qdrant, S3 und Zitadel. Wenn ein Schritt fehlschlägt, bleiben Daten in den anderen Stores erhalten. Das ist ein DSGVO Art. 17-Risiko und braucht einen idempotenten Wiederholungspfad.
Beide sind in PRODUCTION_STRATEGY.md als Blocker vor dem Go-Live dokumentiert.

Das Diagramm ordnet die sechs Probleme nach Kategorie: Ressourcenverwaltung (S3Client-Singleton, Admin-PAT-Caching), Konfiguration (VECTOR_SIZE), Typkorrektheit (as any, falsches Label) und Codepflege (toter Ternary, Shim-Import). Alle sechs sind behoben. Die zwei offenen Punkte (Rate Limiting, DELETE-Atomizitaet) sind als Go-Live-Blocker markiert.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
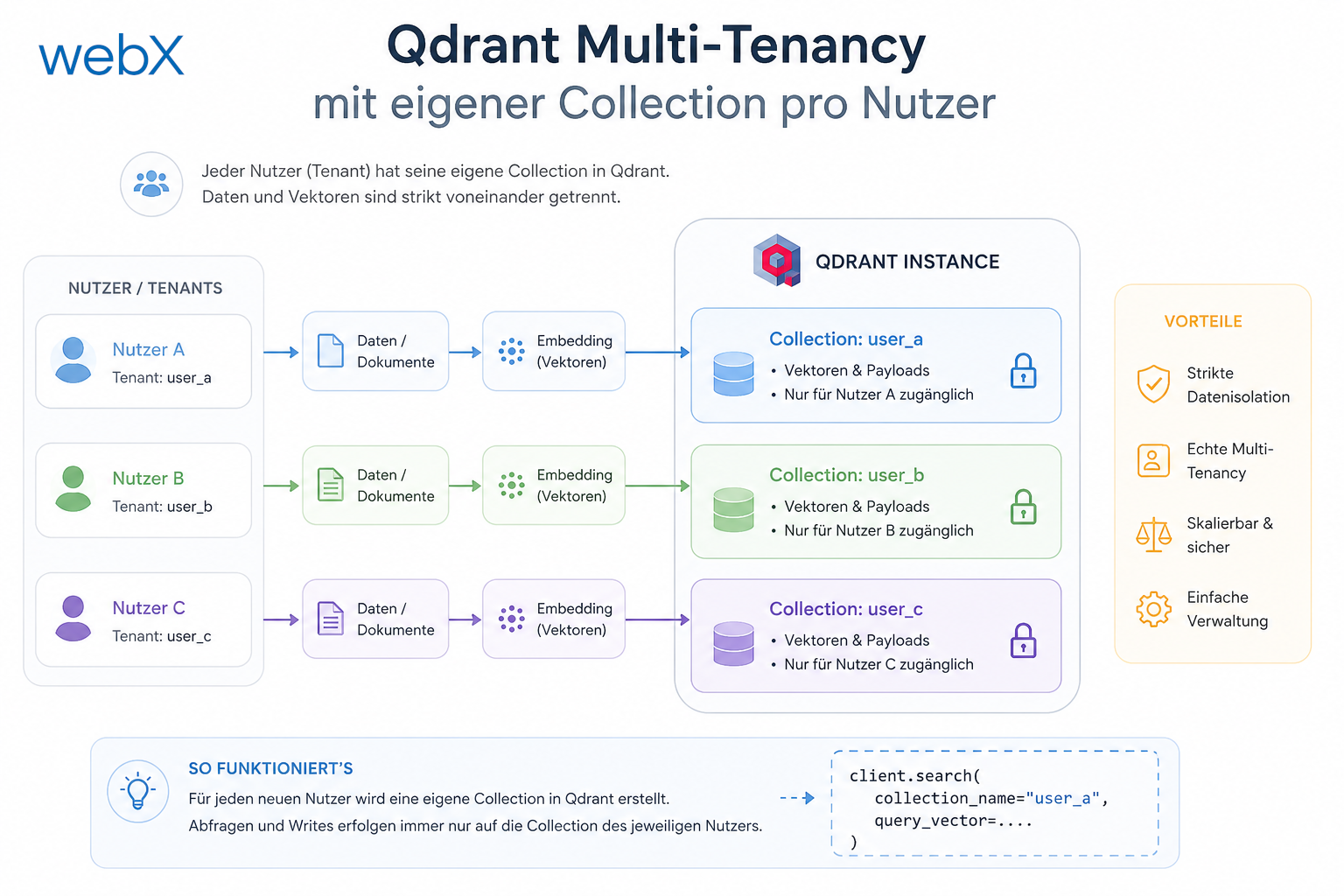
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
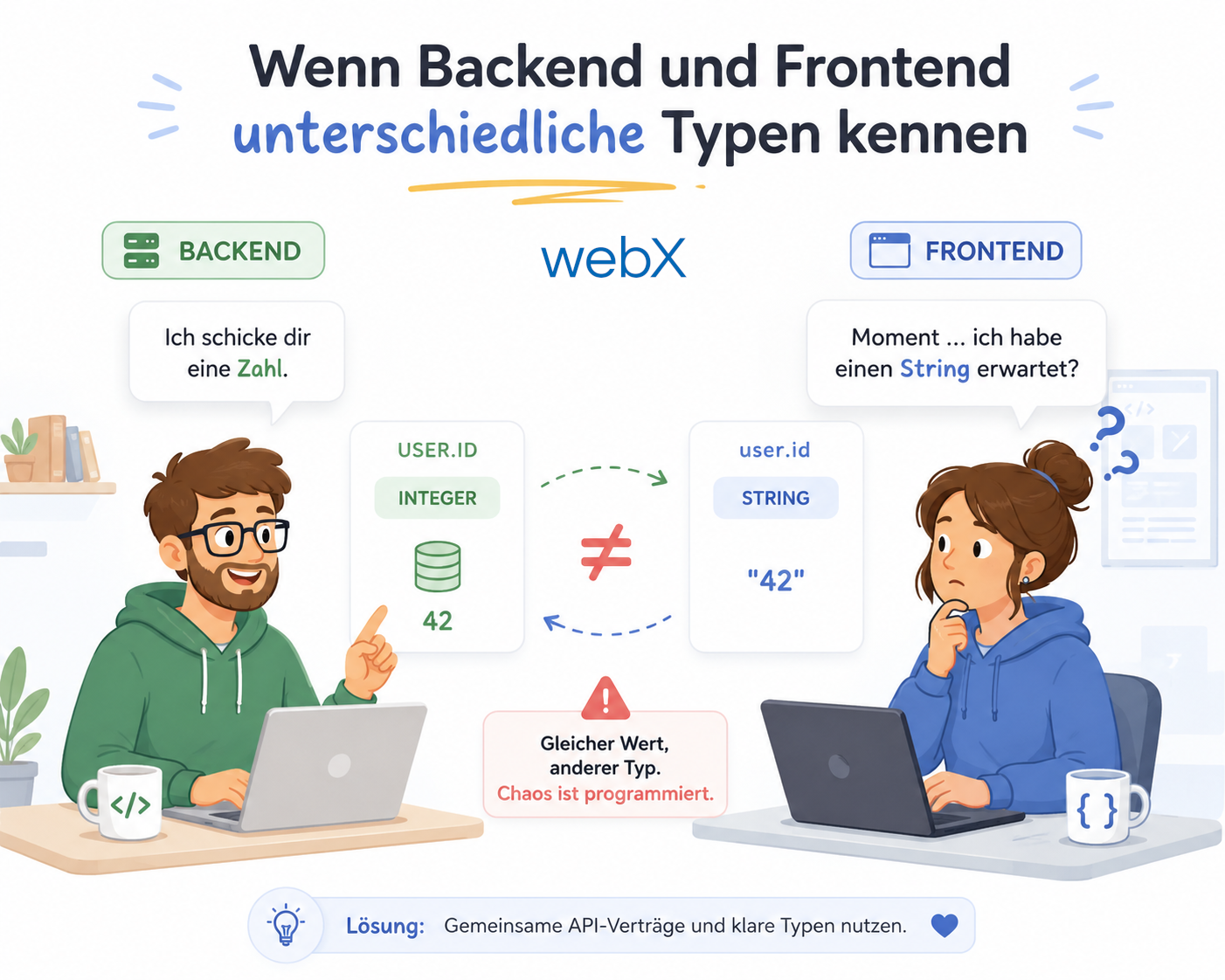
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
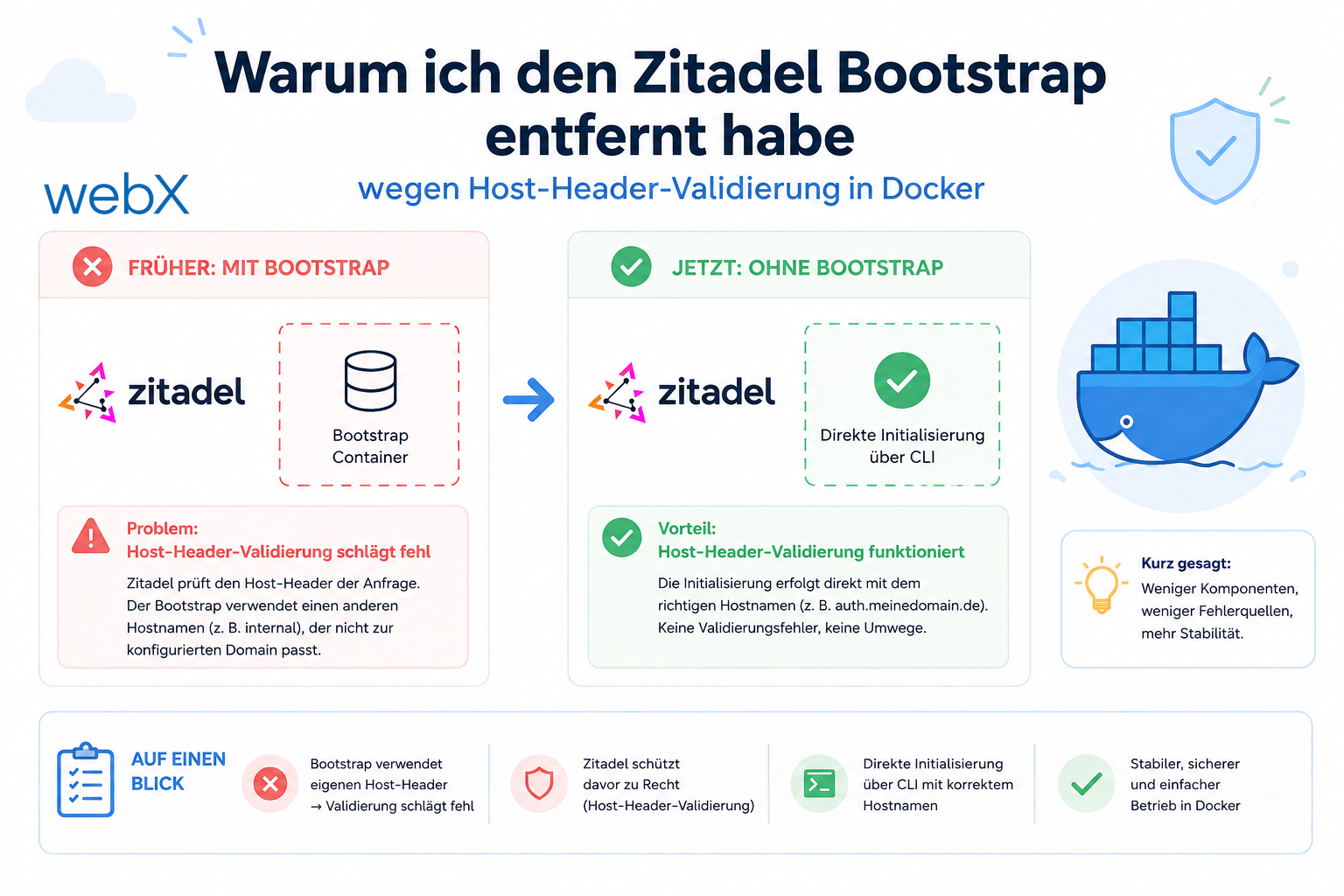
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: (dieser Artikel)
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: Artikel lesen
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du willst dein Backend vor dem Go-Live auf ähnliche Schwachstellen prüfen? Lass uns das gemeinsam einschätzen.