· David Göschel · Architektur · 5 minuten Lesezeit
Wie ich den Embedding Workflow in Qdrant in mehrere saubere Schritte zerlegt habe
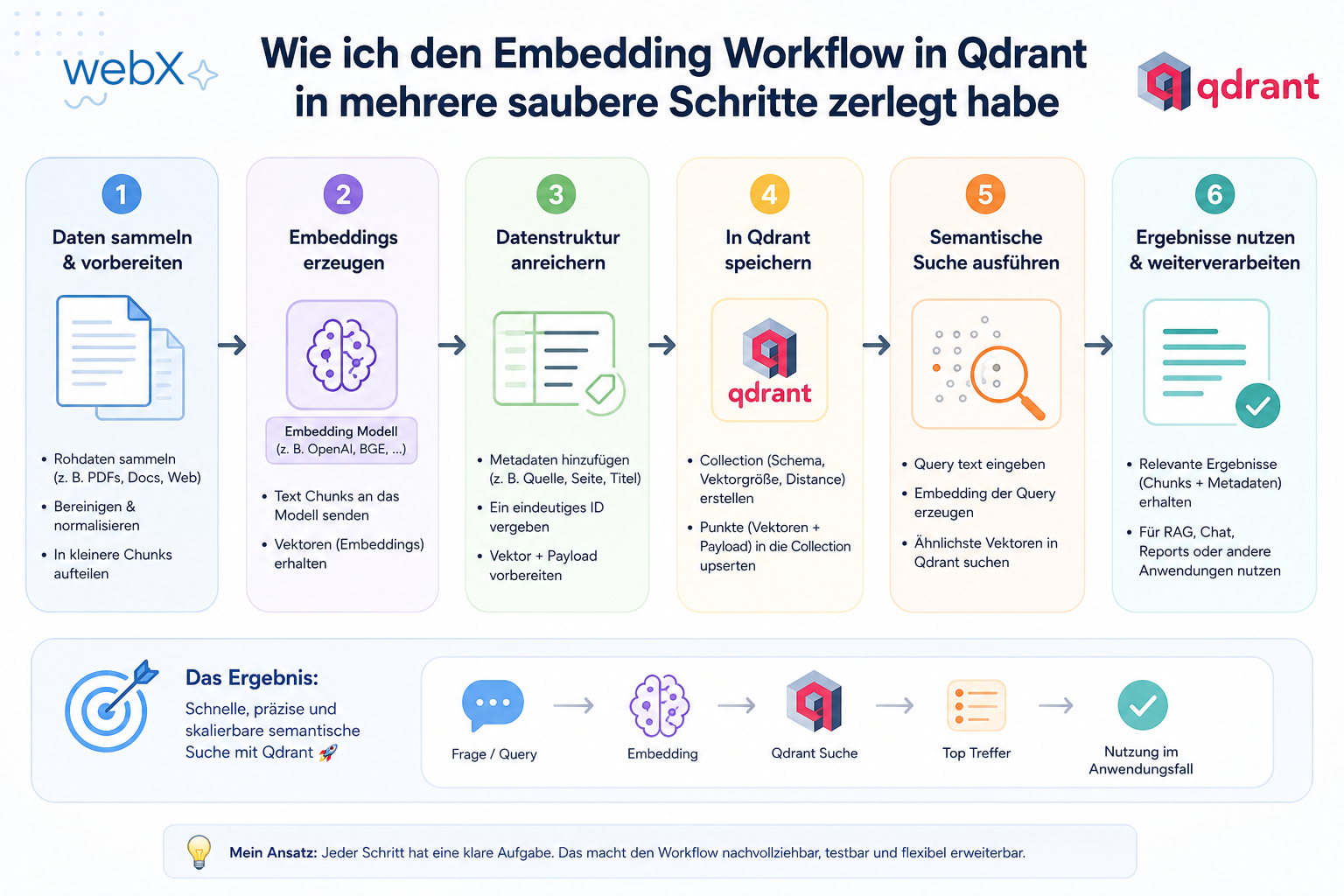
Ich habe den Worker so umgebaut, dass aus einem Capture mehrere Token-Chunks entstehen, jeder Chunk einzeln eingebettet wird, und die Speicherung in Qdrant vollkommen isoliert bleibt.
Inhalt
- Der neue Ablauf im Worker
- Warum ich jeden Chunk einzeln speichere
- Single Shared Collection & Mandantenfähigkeit (Tenant Isolation)
- Atomare Rollbacks für maximale Konsistenz
- Alle Artikel der Serie
Der neue Ablauf im Worker
Nachdem die Diagnose und die strategische Entscheidung standen, ging es an das Refactoring des Ingestions-Pipelines. Statt alles in einem einzigen, fehleranfälligen Schritt abzuwickeln, habe ich den IngestWorker (angetrieben von BullMQ) in eine saubere, mehrteilige Pipeline zerlegt.
Der Fluss lässt sich wie folgt zusammenfassen:
Input text
↓
Fetch Capture Record (PostgreSQL as source of truth)
↓
Build Structured Document (platform-specific strategies)
↓
Token-based chunking (XLM-RoBERTa, 1500 tokens, 150 overlap)
↓
Generate Embeddings (high-speed in-memory cache in ai-provider)
↓
Atomically store points in Qdrant (shared collection, userId keyword index)
↓
Update Database Status (marked as "done")Durch diese feingliedrige Struktur wird aus einem großen, unberechenbaren Request eine Kette überschaubarer und absolut kontrollierbarer Arbeitsschritte.
Warum ich jeden Chunk einzeln speichere
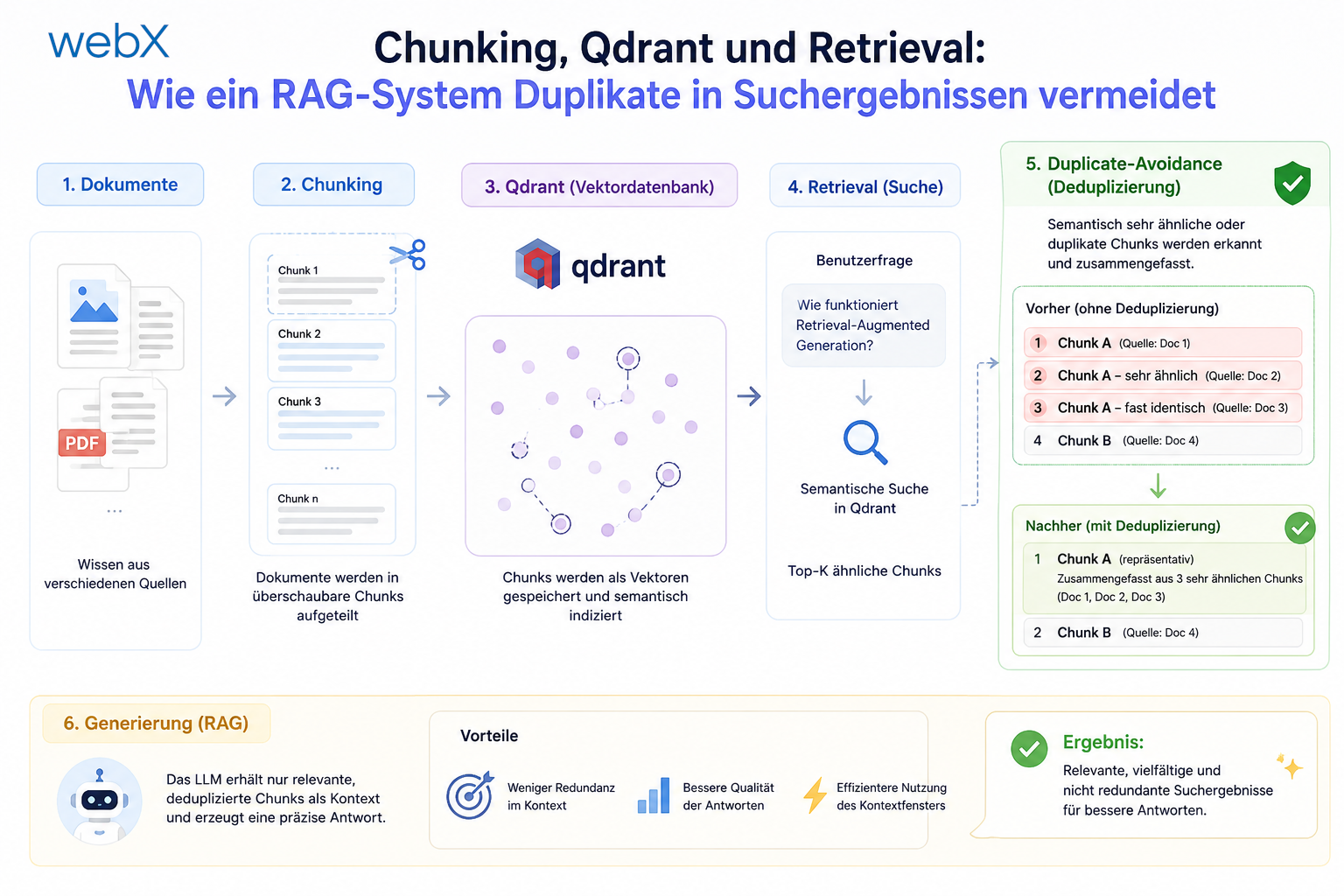
Die Erstellung eines einzigen Vektors für einen langen Beitrag ist ungenau. Wir würden damit wertvolle Detailinformationen nivellieren. Wenn wir stattdessen jeden Chunk einzeln einbetten und als separaten Datenpunkt abspeichern, können wir bei einer Suchanfrage genau den relevantesten Textabschnitt ausfindig machen.
Dazu speichern wir die Chunks in Qdrant mit einer gemeinsamen Referenz ab:
// Storing chunked points with shared metadata for retrieval
const points = vectors.map((vector, index) => {
return {
id: randomUUID(),
vector,
payload: {
...payload,
chunkIndex: index,
chunkCount,
}
};
});Um die CPU- und API-Last gering zu halten, haben wir im AI-Provider einen High-Speed In-Memory-Cache implementiert. Wenn derselbe Textabschnitt erneut eingebettet werden soll (z. B. bei Retries), greift der Cache sofort und verhindert unnötige Modell-Inferenz.
Single Shared Collection & Mandantenfähigkeit (Tenant Isolation)
Ein wesentliches Highlight des Refactorings betrifft das Design der Vektordatenbank. Zuvor hatten wir pro Nutzer eine eigene Qdrant-Collection angelegt. Das skalierte betrieblich jedoch katastrophal und verursachte enormen RAM- und Verbindungs-Overhead.
Jetzt nutzen wir eine Single Shared Collection namens local_insight_memory für alle Benutzer. Die Datentrennung (Multi-Tenancy) wird konsequent auf Applikationsebene durchgesetzt:
- Jedes gespeicherte Chunk-Objekt erhält zwingend das Attribut
userId. - Um eine blitzschnelle Filterung im O(1)-Bereich zu gewährleisten, legen wir beim Serverstart automatisch einen Keyword-Payload-Index auf das Feld
userIdin Qdrant. - Alle Lese- und Suchoperationen erzwingen serverseitig ein Filter-Kriterium auf diese
userId. - Um den Arbeitsspeicherbedarf von Qdrant zu optimieren, werden die Chunk-Payloads radikal entschlackt und enthalten nur noch die minimal notwendigen Metadaten (Tags, Notizen, Plattform, Quellkanal, Zeitstempel,
captureIdunduserId).
Atomare Rollbacks für maximale Konsistenz
Was passiert, wenn der Ingestion-Prozess mittendrin abbricht? Wenn der S3-Upload gelingt, aber das Enreihen in die Queue scheitert, drohen Datenruinen.
Dazu haben wir ein robuste Fehler-Rollback-System im /ingest-Orchestrator implementiert. Wenn ein nachgelagerter Schritt fehlschlägt, werden bereits angelegte PostgreSQL-Zeilen und in MinIO/S3 hochgeladene Bilder sofort wieder gelöscht (deleteCapture und deleteImage). Erst wenn alle Phasen fehlerfrei durchlaufen sind, gilt die Ingestion als erfolgreich.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
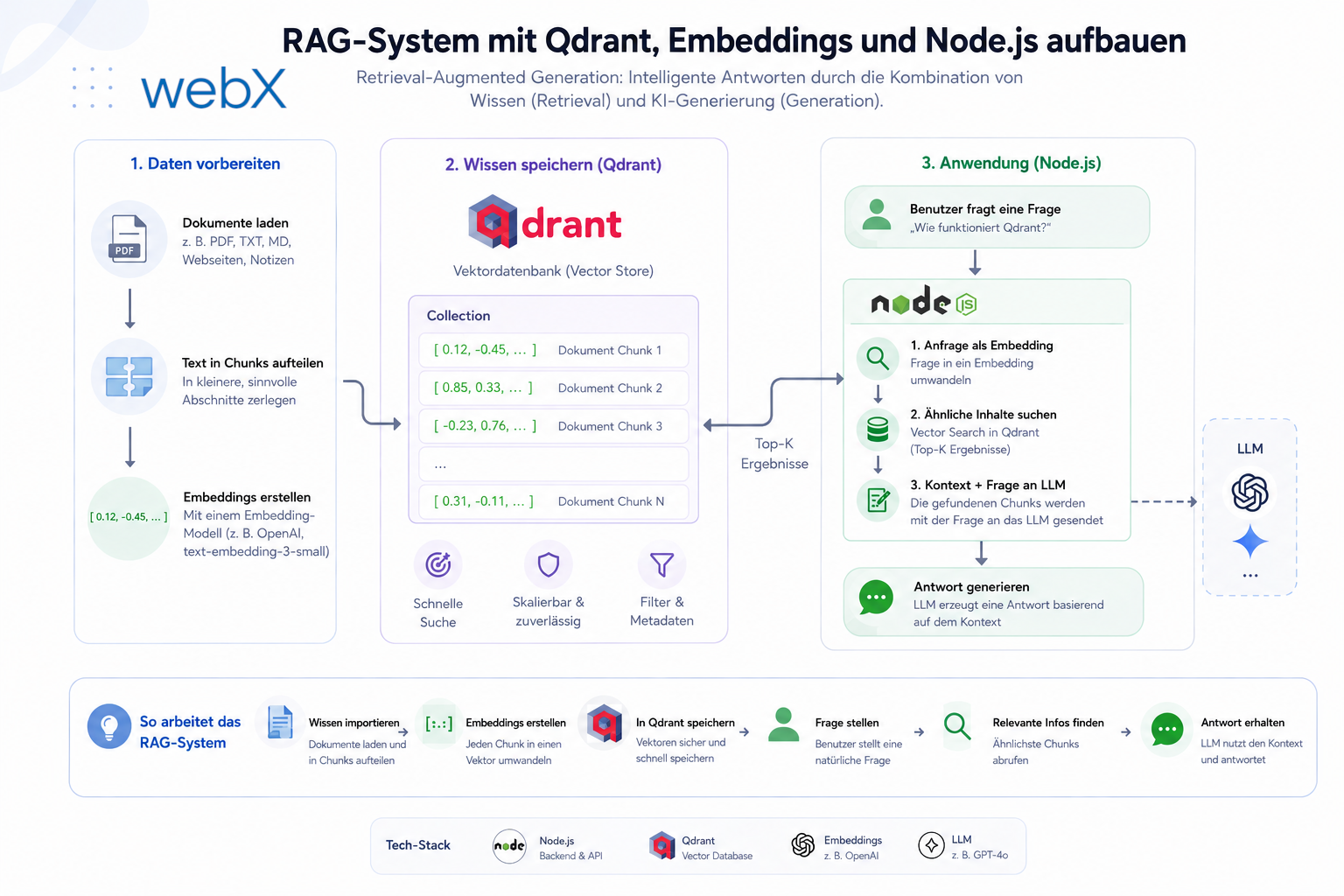
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
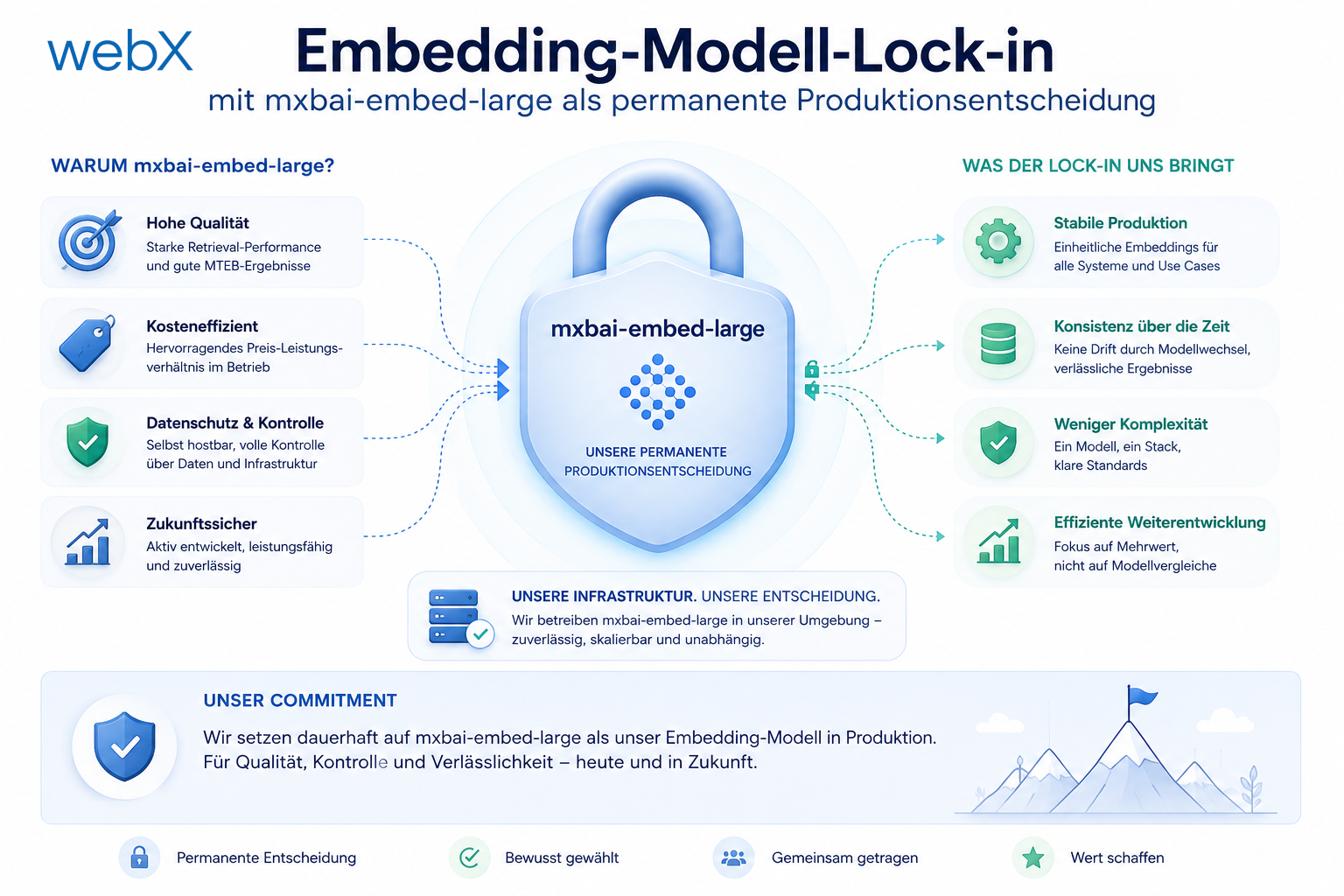
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
- Traefik als einziger Einstiegspunkt im Docker Compose Stack: Artikel lesen
- Zitadel hinter Traefik richtig verdrahten mit Issuer, JWKS und Login V2: Artikel lesen
- Frontend reparieren wenn der nginx Healthcheck an localhost scheitert: Artikel lesen
- Observability für meinen Docker Compose Stack mit Bull Board und Dozzle: Artikel lesen
- Qdrant Dashboard sicher öffnen mit lokalem Traefik und SSH Tunnel: Artikel lesen
- Diagnose: Warum mein Chunking trotz Tokenisierung noch scheiterte: Artikel lesen
- Entscheidung: Warum ich den Chunk auf 1500 Tokens gesetzt habe: Artikel lesen
- Implementierung: Wie ich den Embedding Workflow in mehrere saubere Schritte zerlegt habe: (dieser Artikel)
- Validierung: Wie ich Chunking, Speicherung und Suche wieder zusammenbringe: Artikel lesen
Du arbeitest gerade an einem ähnlichen RAG System und willst die gleiche Struktur für dein Projekt bewerten? Lass uns das gemeinsam einschätzen.