· David Göschel · Architektur
Warum ich den Chunk in meinem RAG-System auf 1500 Tokens gesetzt habe
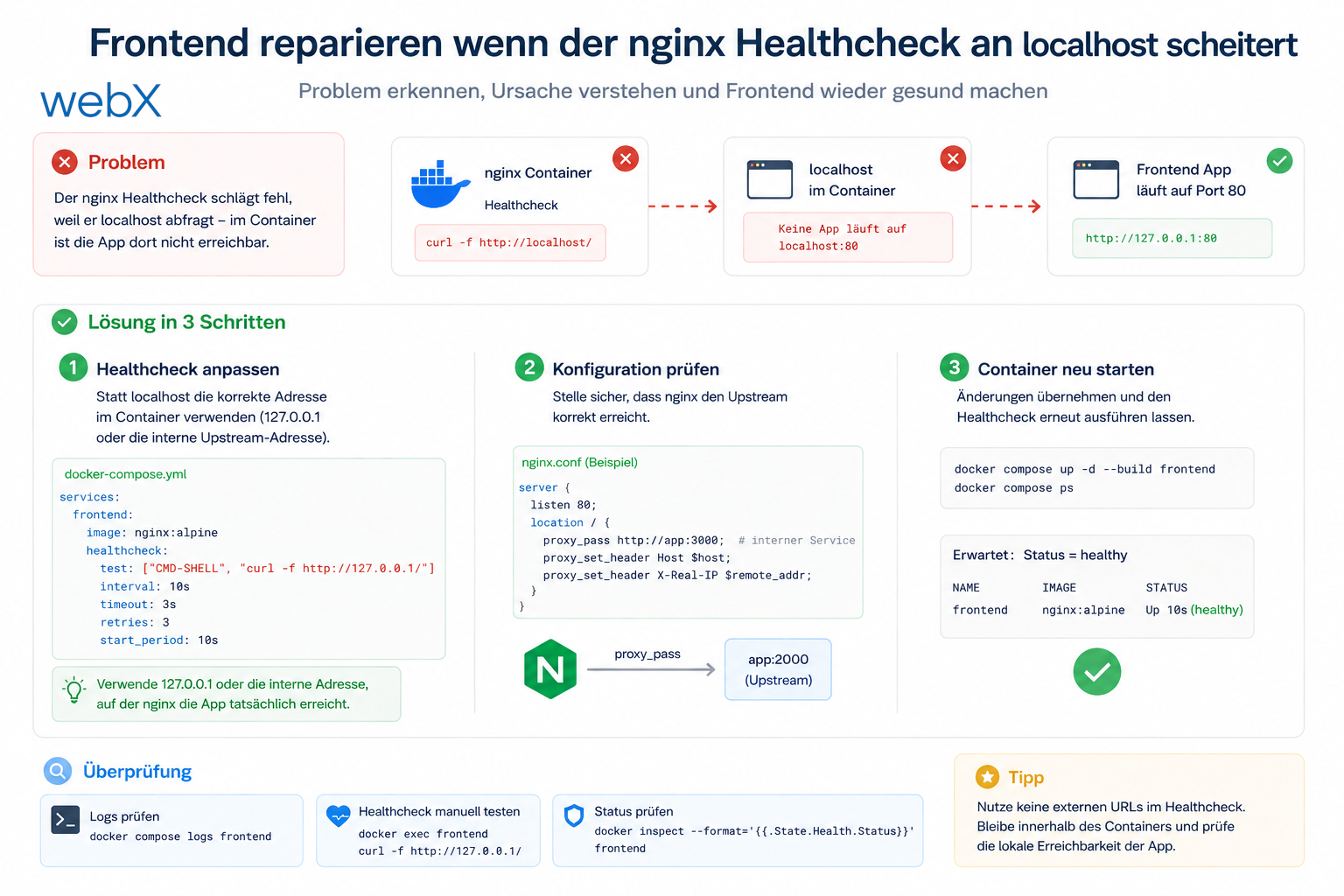
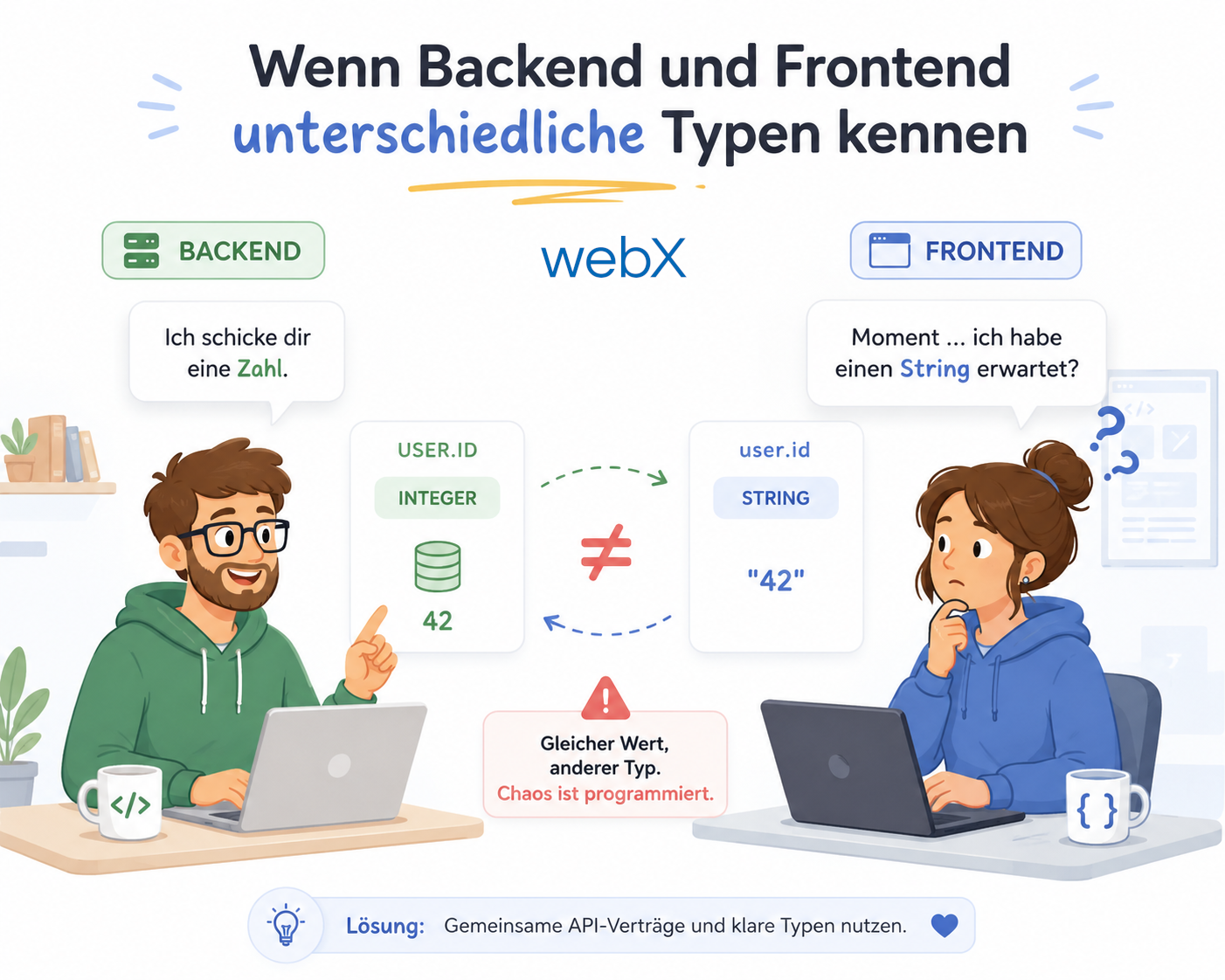
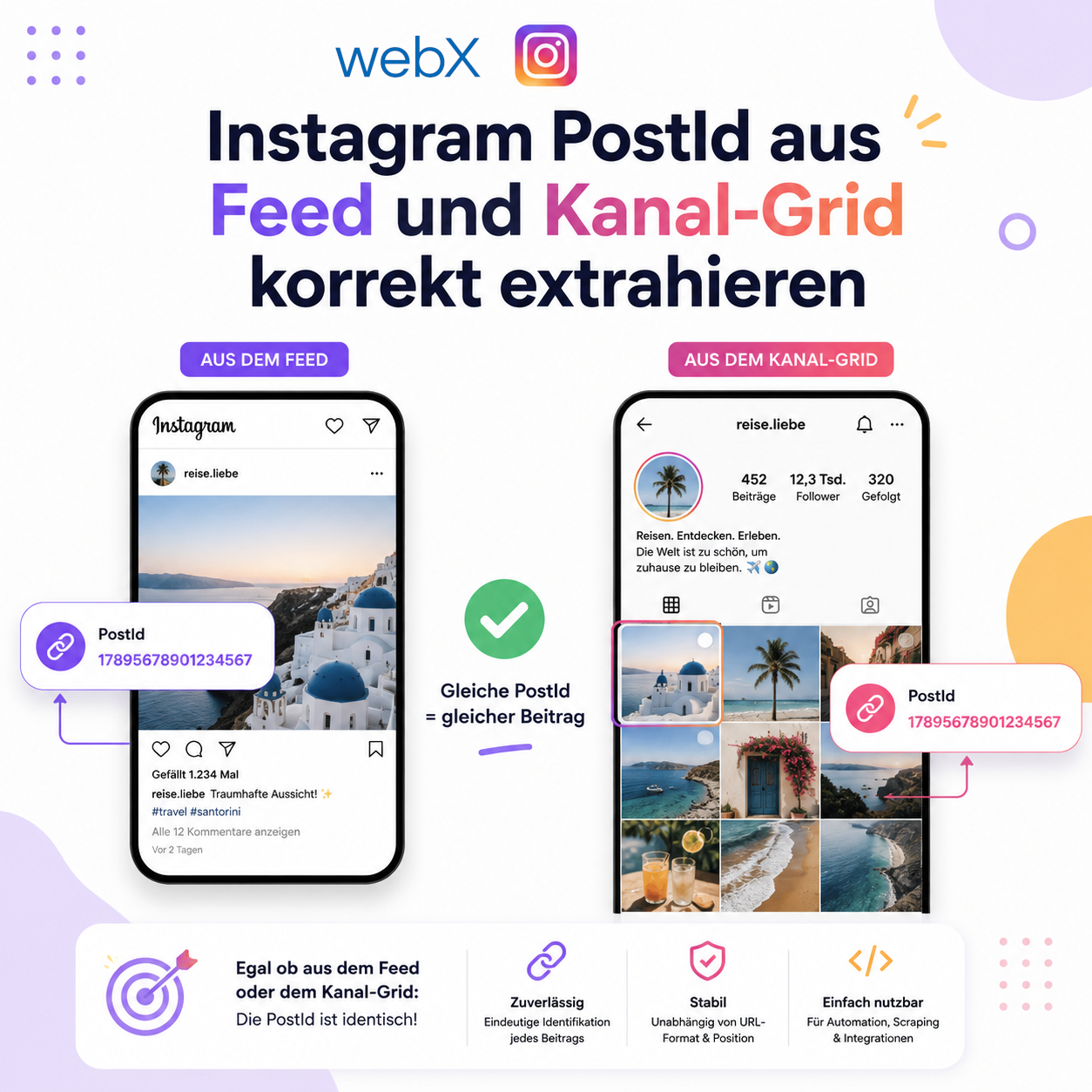
Die Migration auf bge-m3 brachte ein 8192 Tokens Limit. Dennoch habe ich das Chunk-Limit bewusst auf 1500 Tokens gesetzt, um die semantische Schärfe zu bewahren.